- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 整个项目没有一行古法编程,就不截图了
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
上一次是老马拉大车,这次轮到手头的这个国产小板子(香橙派AI Pro,昇腾310B芯片)。由于国产生态问题,其实这个板子很少有人去适配模型,而最近面壁智能发布了MiniCPM-V-4.6,小钢炮的SOTA,主打一个端侧和手机运行的小模型,能力也很不错:
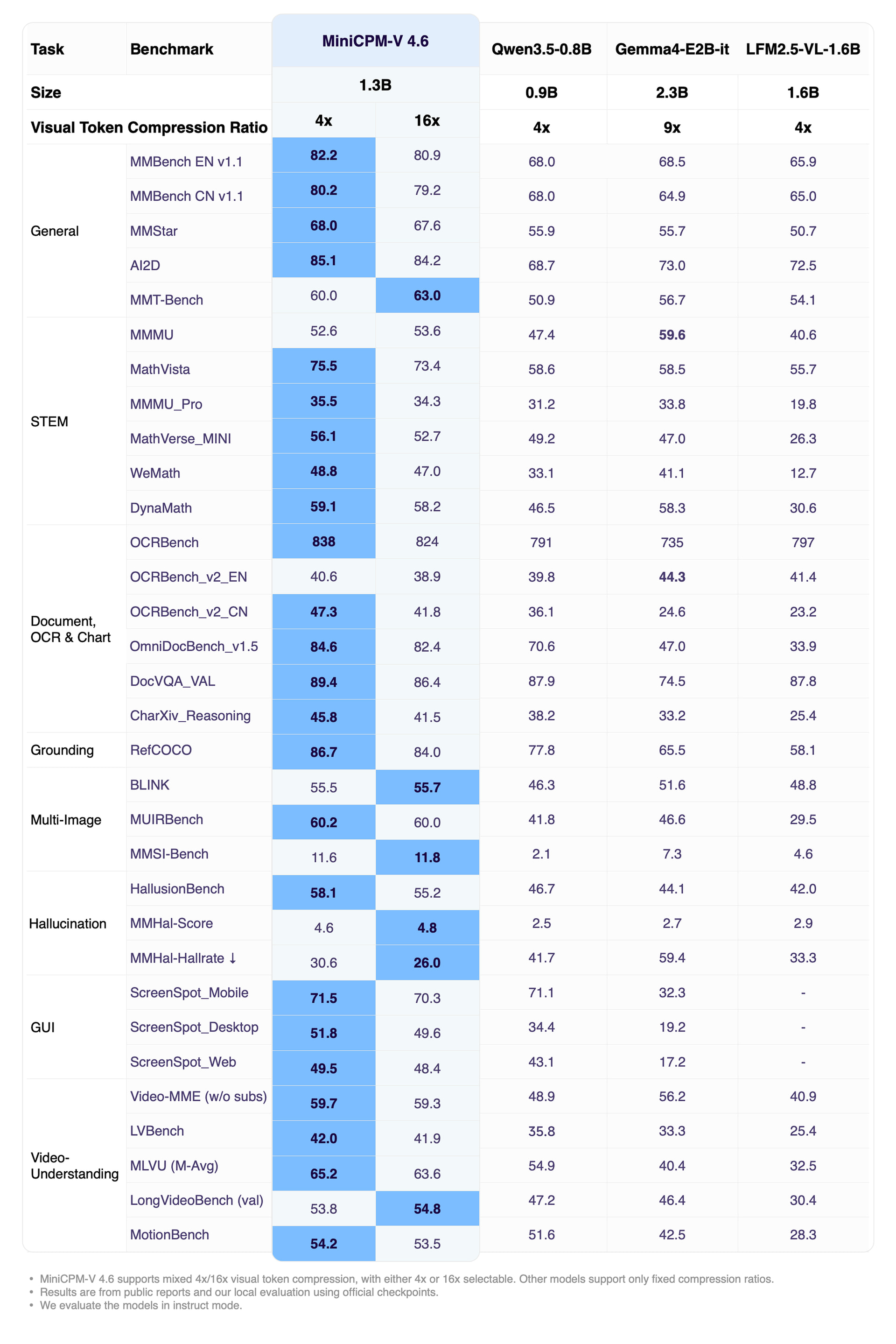
而我们这个板子呢,虽然算力不高,但是跑个1.3B应该还是绰绰有余的。


20TOPS版本大概2000块,8T版本更便宜,只要899。折合一下FP16算力差不多也有1080TI水平了,用的unified memory, 24GB内存。最近没啥人折腾,还是要祭出天才程序员,这次不是写CUDA,而是写AscendC自定义算子,把MiniCPM-V-4.6支持起来。下面是项目介绍:
一个完全从零写的 C++/AscendC 推理引擎,把 MiniCPM-V 4.6 跑在 Orange Pi AIPro 20T 板载的 Ascend 310B NPU 上。 文本和图像对话都完全跑在 NPU 上,Python 端只在 CPU 上做 tokenize 和图像预处理,推理热路径完全不依赖 torch_npu。
通过三轮 cube unit / 自定义 kernel 工作,单 batch 解码从 2.88 → 5.90 tokens/s(~2×), 跑的是完整 24 层 hybrid 线性 + full attention 模型(hidden 1024,vocab 248094,fp16):
阶段 Tokens/s 单步耗时 (ms) 节省 原生aclnnMm baseline
2.88
350
—
+ 自定义 cube matmul(M=1)
4.37
229
121
+ lm_head 切 16 块走 cube
4.99
200
29
+ 向量化 causal-conv1d step kernel
5.90
170
30
测试条件:prompt_T=8,decode 30 个 token。剩下的 ~170 ms / step 主要被 matmul 权重带宽吃掉;下一步只能上权重量化(见 Roadmap)。
视觉塔(SigLIP-so400m → vit_merger → 投影到 LM hidden,总共 27 层 transformer) 也已经移植到 C++/aclnn,端到端对照 HF CPU 参考实现验证过:最终给 LM 用的 image_features 跟 HF 输出的 max_abs_diff = 0.0098(448×448 输入)。

总体来说上量化版本还有很大的优化空间,先放出来给大家玩玩。项目链接:GitHub - lvyufeng/minicpm-v-4.6-orangepi · GitHub
欢迎大家Star和折腾。
7 个帖子 - 4 位参与者