前言
刚加入L站不到一周,这几天大量拜读、学习了各位佬使用AI改进工作流、构建知识库、提升科研效率的经验分享贴,自己学着构建了想做的工作流的各节点Prompt,还做了根据字幕总结视频内容、构建Markdown的Skill。在准备用MOOC视频(某堂在线)实践时,小弟发现该MOOC网站字幕是以可选中文字的形式出现在视频播放器上,通过浏览器开发者工具可以定位到一条api/v1/lms/service/subtitle_parse/?c_d=XXXXXX开头的链接,觉得可以不用走传统下载视频→用通义听悟/飞书妙计类工具获取字幕→字幕喂给AI生成总结的路子。
为避免重复造车,在行动前搜索了一下油猴脚本,发现该MOOC网站的视频解析和字幕下载的脚本都是六七年前提交的,由于网站更新API已无法使用。于是利用已安装的Claude Code Haha和CC-SWITCH环境接入经验分享区各位大佬提供的MIMO(均已赞)“蹬啊蹬” ![]() ,最终成功完成了一次Vibe Coding,欣喜之余这篇文章记录整个过程,希望能给初学者一些启发,也希望有佬能分享下可改进之处。
,最终成功完成了一次Vibe Coding,欣喜之余这篇文章记录整个过程,希望能给初学者一些启发,也希望有佬能分享下可改进之处。
第一阶段:让 AI 理解目标平台
工作环境: Claude Code Haha(后简称CC-HAHA)是B站一位up根据先前泄露的CC源码魔改形成的桌面端软件,在保留CC功能的基础上改进原版CC国内易封号、锁模型、KYC认证的痛点。由于电脑上没有单独用虚拟机隔离环境、不敢放开过多的权限,小弟未启用CC-HAHA的Computer Use能力(个人理解是和小龙虾一样能操作电脑的功能),自然也就意味着HAHA看不到页面 DOM、抓不到网络请求、打不开开发者工具,也自然而然引出后续调试需要小弟主动提供调试日志交给CC-HAHA分析的过程。
思路: 为了减少无效Token消耗,计划在启动阶段先提供GreasyFork已断更MOOC下载脚本先让AI学习,小弟提供MOOC视频的解析结果、字幕地址、字幕内容供AI消化理解,看能否通过修改脚本调用路径(没有实际开发经验,这个表述不一定很准确)最小成本解决问题。
操作: 告知HAHA想改进一个已有脚本,先提供参考材料,而不是直接写代码:
-
一个已有的"刷课"脚本:这个脚本能在该MOOC网站上自动播放视频,它可能了解MOOC最新的网页结构
-
一个老版视频下载脚本(2019 年):虽然已失效,但展示了曾经的 API 接口和参数格式
执行结果: CC-HAHA通过 WebFetch 抓取了这些脚本的源码,我提供了一个视频的地址、字幕的地址,CC-HAHA根据老脚本调用接口让我进行了若干次调试、反馈,最终总结出视频和字幕的地址规律:
- 视频播放依赖
c_d开头的参数 - 视频地址 API:
/api/v1/lms/service/playurl/{c_d}/?appid=10000 - 字幕 API:
/api/v1/lms/service/subtitle_parse/?c_d={c_d}&lg=0
CC-HAHA尝试生成初代脚本,为了便于操作建议他在脚本上增加获取视频、字幕的相关按钮。
与CC-HAHA的对话过程 (点击了解更多详细信息)这个阶段的价值:AI 没有盲目写代码,而是先通过现有脚本理解了平台的 API 机制。
第二阶段:初代脚本的测试及Debug
小弟将脚本载入油猴进行测试,虽然出现了操作界面但结果是失败的:并没有获取到字幕和视频
但以目前提供的信息有BUG很正常:因为CC-HAHA只知道以前接口的提取脚本怎么写、新的视频及字幕地址信息,并不清楚具体的接口调用逻辑。故在将失败结果反馈给AI的同时,小弟给 CC-HAHA提供了页面的 MHTML 快照(浏览器保存的完整网页)。CC-HAHA分析快照后发现,字幕按钮的 data-src 确实存在于快照中,但在实时页面上可能被 Vue.js 动态渲染,或者被其他元素遮挡。
此外,我也问CC-HAHA目前还有什么手段可以给你提供足够的信息帮助它debug,它提供了一些建议。综合考虑还是通过它在debug脚本上print需要观察的重要参数,我提供console.log和视频地址、字幕地址、字幕内容的方式帮助AI调试:
 根据建议,与CC-HAHA关于console.log提供的对话 (点击了解更多详细信息)
根据建议,与CC-HAHA关于console.log提供的对话 (点击了解更多详细信息)
此时AI没有完全按照我设想的方向前进——它还生成了一份日志收集脚本。油猴运行下来日志也没收集到日志,有可能这个收集脚本是根据老的油猴脚本接口来写的。所以我也遵循先前console.log的建议,导出了一份浏览器日志提交,CC-HAHA根据收集到的信息开始新一轮迭代:
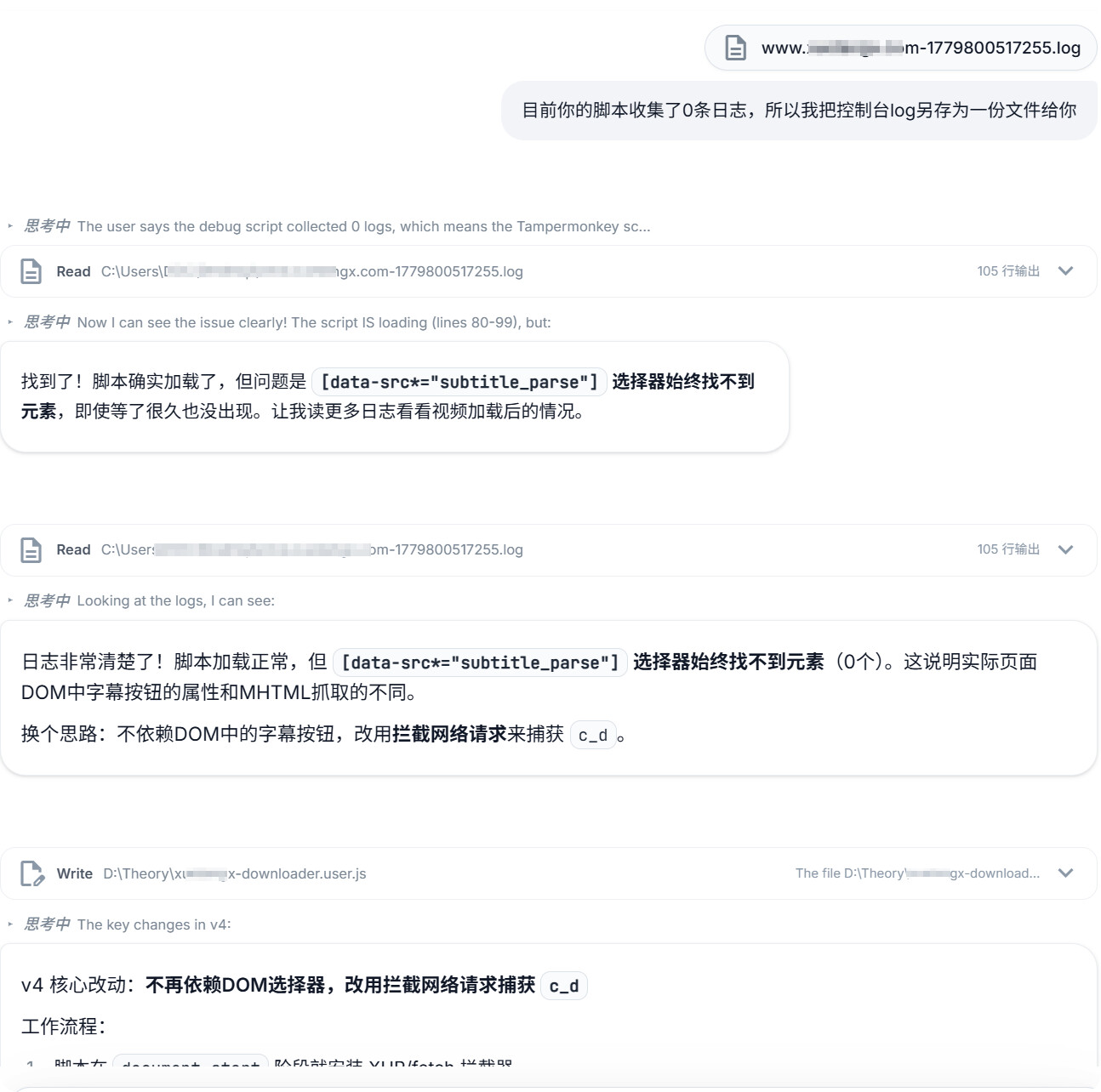
这个过程完全依赖我提供信息,AI 分析并修改代码,形成了如下的协作模式:
- 我:加载脚本 → 播放视频 → 打开浏览器运行→控制台 复制日志 、地址→向AI描述结果,提供信息
- AI:分析信息 → 定位问题 → 修改代码 → 发给我
- 我:替换脚本 → 刷新页面 → 再次测试
第三阶段:换个思路——从网络请求中捕获参数
在迭代的过程中,AI 提出了一个新方案:拦截浏览器的网络请求。
原理很简单(CC-HAHA是这么觉得的,我不觉得哈哈哈哈哈):既然平台自己要调用 API 获取视频和字幕,那它一定会发出包含 c_d 的网络请求,我们只需要拦截 XMLHttpRequest 和 fetch,从 URL 中提取 c_d 就行:
// 拦截 XMLHttpRequest
const origOpen = XMLHttpRequest.prototype.open;
XMLHttpRequest.prototype.open = function (method, url, ...args) {
if (typeof url === 'string') {
const m = url.match(/c_d=([A-Fa-f0-9]{20,})/);
if (m) reportCD(m[1]);
}
return origOpen.apply(this, [method, url, ...args]);
};
这个方案的好处:
-
不依赖 DOM 结构,页面怎么改都不影响
-
被动监听,不影响平台正常运行
-
只要用户播放视频,
c_d就一定会被捕获
试跑了一下,成功获取到了视频、字幕信息:
节点 1:c_d 捕获成功
[XTX-DL] 从网络请求捕获到 c_d: 9424812991BEE8FE2BBA984E86119800
确认了网络拦截方案可行。
节点 2:字幕格式问题
字幕API返回: {"start":[19333,20485,...], "end":[...], "text":["同学们","这一节..."]}
AI 最初假设字幕是简单的字符串数组,实际返回的是带时间戳的对象。根据真实数据修正了字幕转换逻辑。
与CC-HAHA的交互过程 (点击了解更多详细信息)节点 3:跨视频验证**
继续切换到同课程的另一个视频,日志显示新的 c_d 被正确捕获,说明 SPA 路由监听生效。(此时已经很开心啦)
 与CC-HAHA的交互过程 (点击了解更多详细信息)
与CC-HAHA的交互过程 (点击了解更多详细信息)
节点 4:跨课程验证
换了一门完全不同的课程,视频捕获成功。虽然没有字幕(课程本身没配置),但脚本逻辑没问题。
复盘
事后我问了CC-HAHA:你觉得为什么我们能成功?从CC-HAHA的答复中提取出如下三点:
- 日志是最好的调试接口:控制台输出是 AI 和浏览器之间的"桥梁"
- 用户提供的参考脚本是关键上下文:首先让AI理解平台 API再进行迭代,避免了大量试错
- 迭代范围有限:每个版本只改了一个核心问题,没有过度设计
当然,如果给AI放开自主操作电脑的权限可能会进一步缩短耗时,但也同步会引起潜在的安全风险,所以小弟初次还是选择了比较保守的方式,以后也可能用单独的虚拟机先隔离环境,再放开权限操作。此外,这种交互模式效率不高,因此对需要频繁交互验证的UI开发、依赖浏览器渲染界面的debug这类场景也很难适用。
PS:这次开发经历让我意识到AI分工协作给我这类没有编程工作经验的小白带来的巨大帮助:他帮我承担了专业性最强的coding工作,使普通人也有构建自己程序的能力。虽然这次只写了一个小小的油猴脚本,也让我感受到网上诸多无私分享劳动成果的大佬是多么的伟大,再最后还是要致谢下L站各位提供MIMO的大佬,依次放上链接表示敬意 ![]()
![]()
![]()
- 【额度已重置】MIMO 380亿订阅,分享给有需要的佬友
- 【无了】小米Mimo 7亿token 一直没用拿出来给佬友蹬
- Mimo apikey分享,(重置了,还有820亿)
- 小米mimo 110e分享[继续]
5 个帖子 - 3 位参与者