- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
历时两个月,每天平均蹬了gpt 2到4亿token,现在我宣布,1flowbase终于可以发第一版了,终于可以端上来和各位佬们唠嗑唠嗑了。
为什么要做这个项目?
因为我对于本agent中间过程实在很好奇,Claude code 里面是怎么拼接提示词?
为什么有时候我打一个hi?token就狂涨?我们在给Hermes 或者openclaw里面发送了一个消息,他到底干了多少事?
如果我们要构建Hermes 工程,那么我认为首先我们要能观察到模型在干嘛,然后针对他机制,进行文件,提示词优化,不同提示词之间,tokens消耗是多还是少,一切都一切,目前都没有一个让我满意项目,所以我决定自己手搓。
前后端分离,前端打包成静态文件,后端用rust,数据库使用pg,原本有redis我也干掉了,因为我目标是轻量的单机部署,我希望哪怕是1c1m的小鸡都能跑的起来,但是实际上我也没跑起来过,如果有佬跑起来,如果可以的话,分享一下他的资源情况,我想要看看他消耗如何。
好吧,言归正传,为什么我这么执着看到ai调用整个过程?
因为我认为看到,感知到才是调教ai 第一步,就像是22年毕业当后端实习生那会儿,系统报错总是喜欢疯狂打印日志debug,println(“日志–”)。
我认为本质上软件工程和调教ai Hermes 工程并没有太多本质区别,或者我认为
写代码就是给机器写规则,写提示词构建Hermes 其实是给ai写规则。
当然也有很多佬,会表示,其实现在模型很强大了,直接说就可以了,完全没必要调教。
是的,对于个人来说是这样,但是对于一个商业化项目来说这里涉及 成本,单位经济。
在互联网时代,我们软件开发好之后,丢到线上,代码能跑,基本上就能坐着收钱,所以吕氏春秋有云"互联网逻辑,就是先免费,再收钱。"那个时候大量免费,广告行业蓬勃发展。
但是在ai时代,大模型算力,API成本,改变了这个逻辑,烧钱成本剧增,并且带来一个单位经济问题,成本,正常来说个人和中小企业其实都是调用大模型产商的API,然后你就会发现,
ai越强大,价格越贵,效果越好,用户用得越爽,你成本越高,如果没有做好单位经济计算成本计算,那么你就发现一个事情,用户越多,亏得越多。
当然对于openai,anthropic 这些有着资本支撑,这些都不是问题,亏的越多,烧的越多,所有都会狂欢,但是对于我们这些没有资本支持普通ai创业者来说,你就发现,如果要开放ai能力,tokens的单位经济就是一个必须要算账。
但是小模型成本低干不了活,高级模型模型能干活,但是贵。
那么他们可不可以组合起来呢?当然可以了,Claude code 很多本地agent都是这样让低参数模型去总结的。
但是这样有两个问题:
1.只能用一个厂家大模型
2.客户端在用户本地,你每一次更新,其实根本不在你这个服务提供者手中。(我预判一些朋友开始谴责中转掺水问题,但是1flowbase 没有反代。。。我们提供是事无巨细的详细日志和组合)
1flowbase当前第一个版本就是解决这个问题
虚拟模型(Virtual Model)
虚拟模型就是指,你可以通过工作流编排组合你agent大模型供应商,对于本地agent工具如Claude code ,codex,openclaw, Hermes ,aionui,来说他们是无感,他们接入大模型接口就像上游大模型一样。
可以这样编排工作流
串行
手动组合Deepseek V4 多模态让LLM顺序执行,比如说你在Deepseek v4前面套一个Gemini 作为视图,这样用户甩一个图片过去,让Gemini 看完图之后,总结将文字信息和用户问题发给Deepseek,让Deepseek 像多模型一样干活。
手动控制不同厂家模型同一个任务不同工作节点环节我们知道,每一个家大模型都是各有所长,并且长上下文有腐烂问题,
那么我们是不是可以,发一个任务,gpt先干完后端和功能,然后再给Gemini 美化前端页面
智能路由:
还是上面例子, 我们可以不可以先让一个LLM分析当前这个任务应该给哪一个节点,然后再分发到对应节点,比如说后端实现给gpt,前端ui美化分发给Gemini。
使用教程
你可以在大模型供应商里面配置你的模型,目前支持国外御三家和Deepseek:
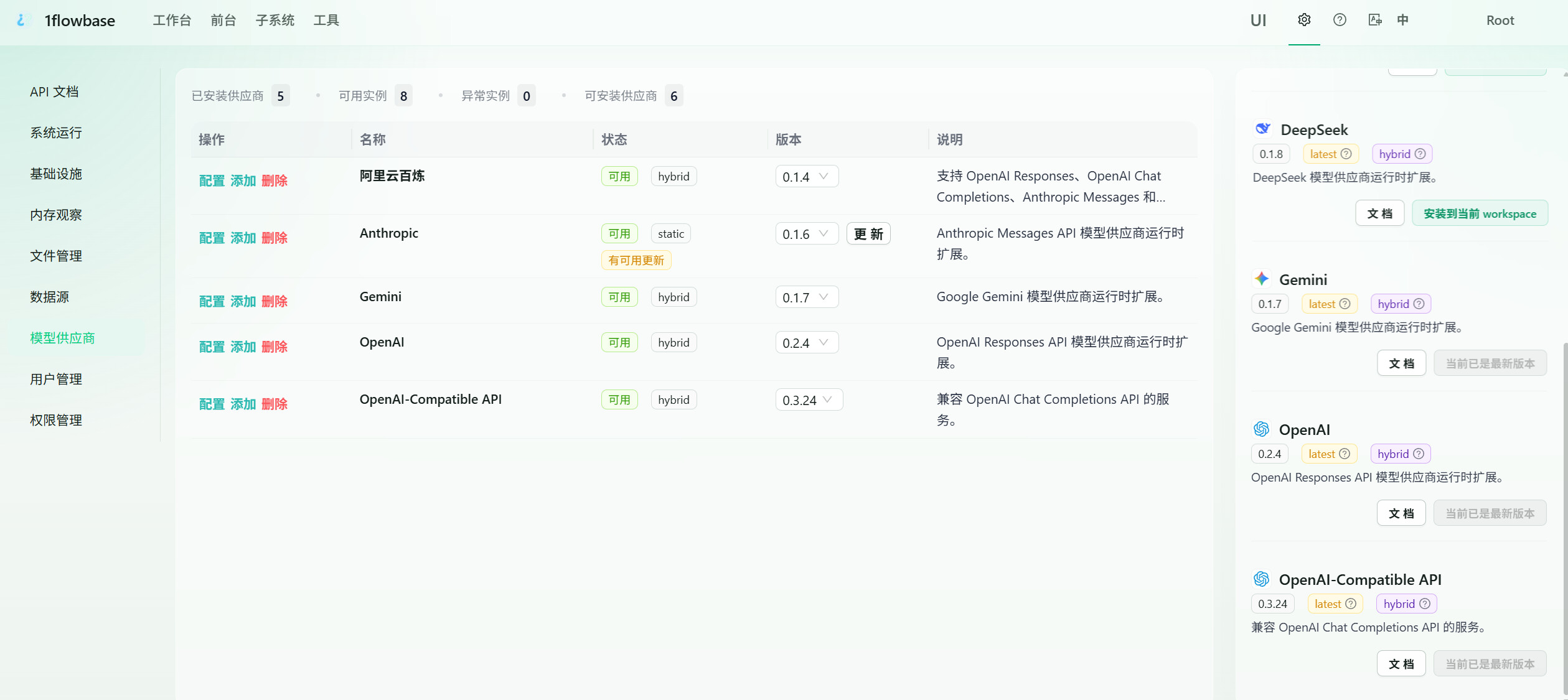
然偶在工作流编排的LLM节点选择你配置模型:

然后直接发布为你openai/anthropic的兼容API 接口
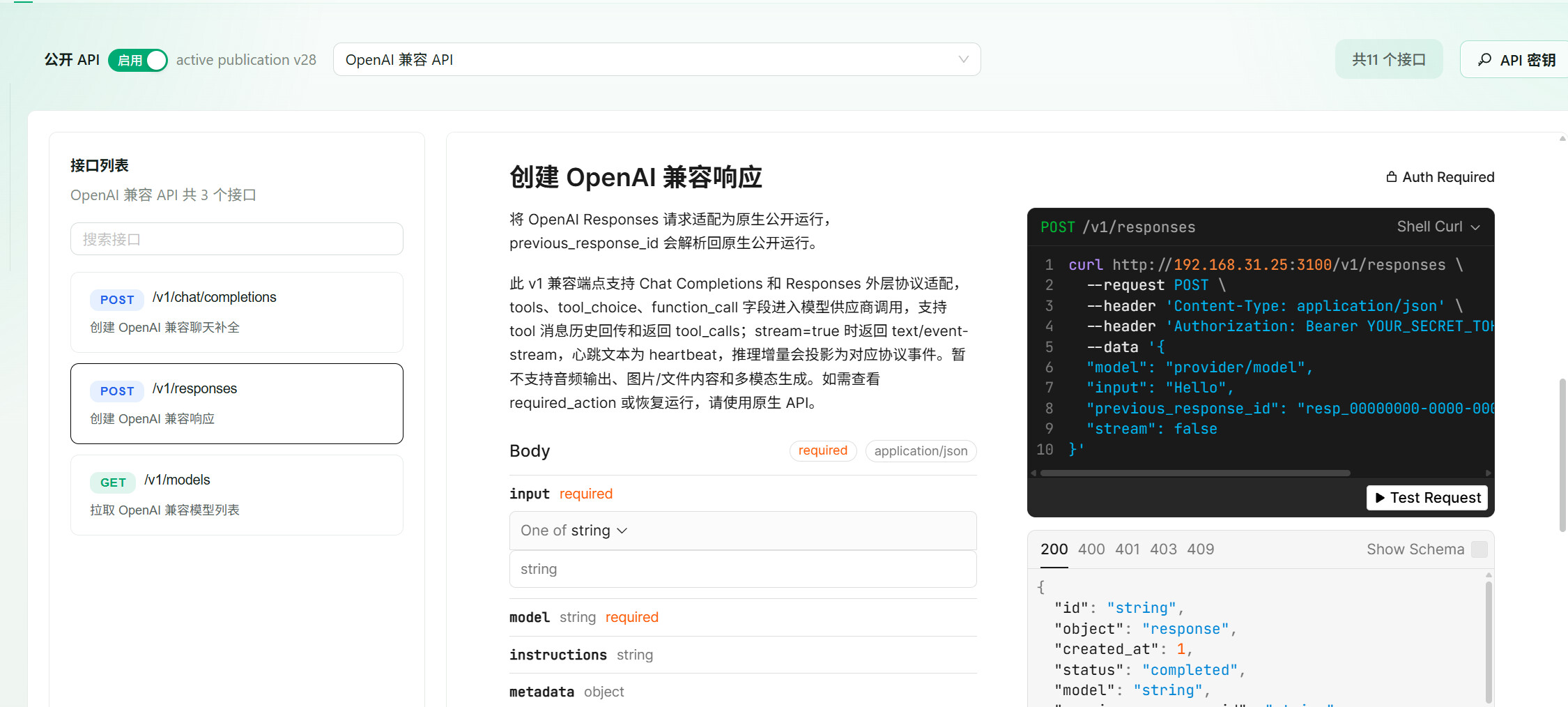
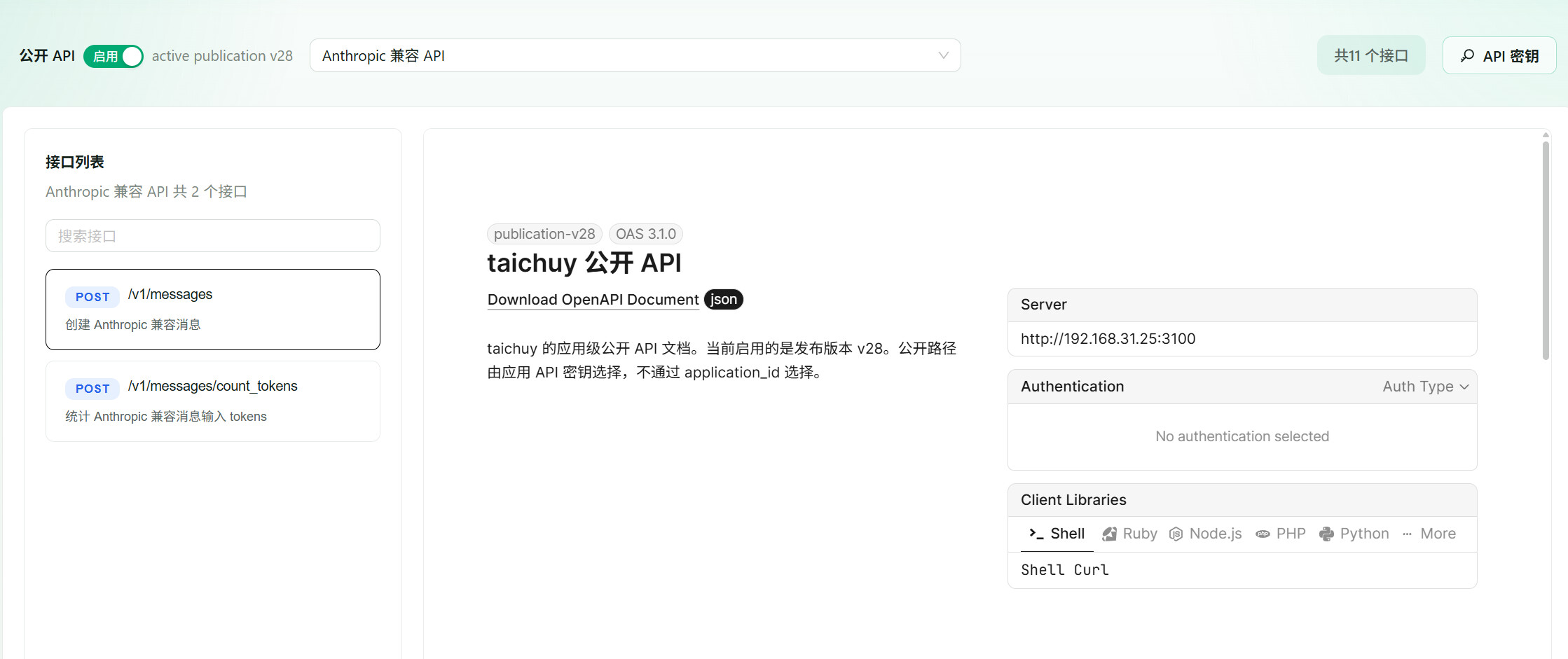
然后你就可以将这个模型放到css中:
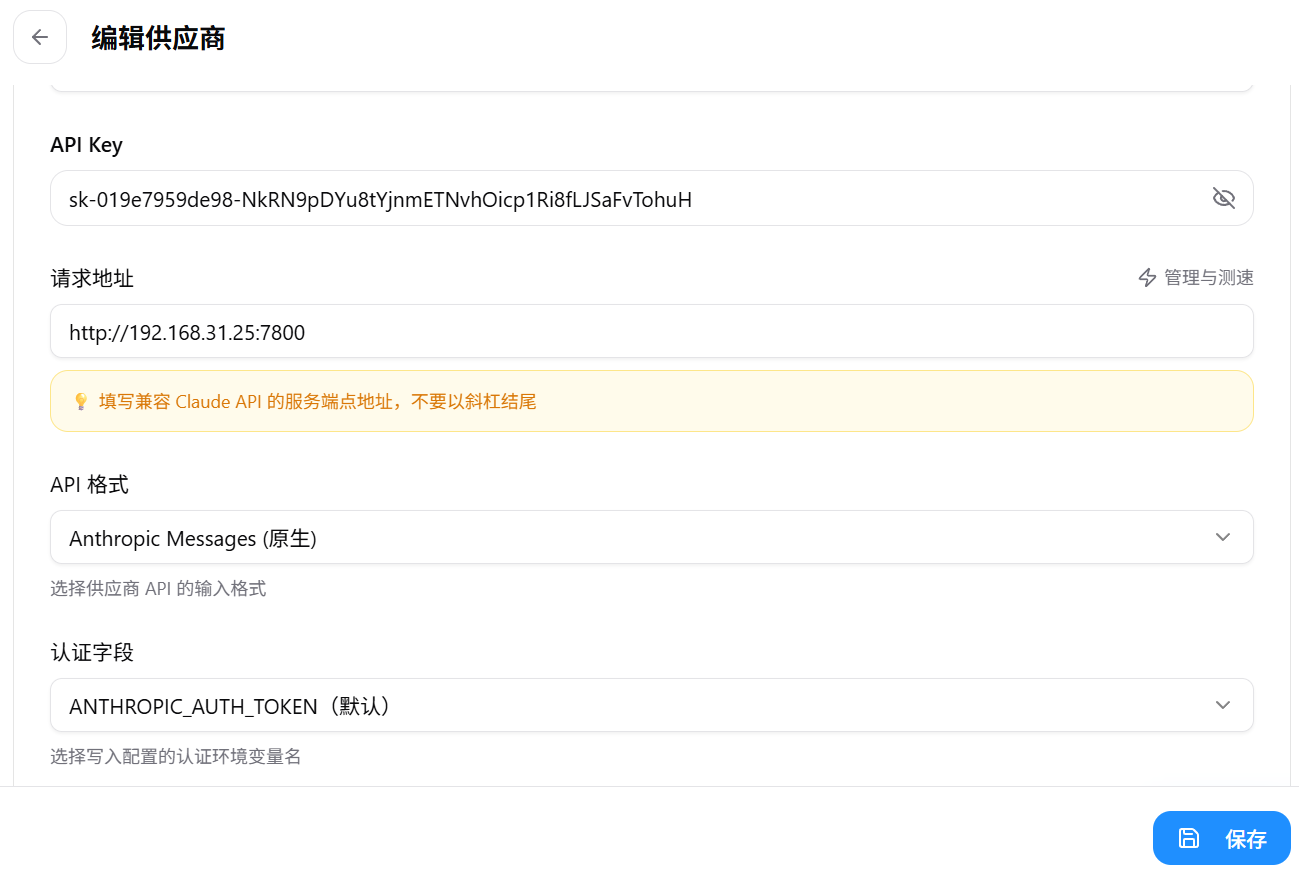
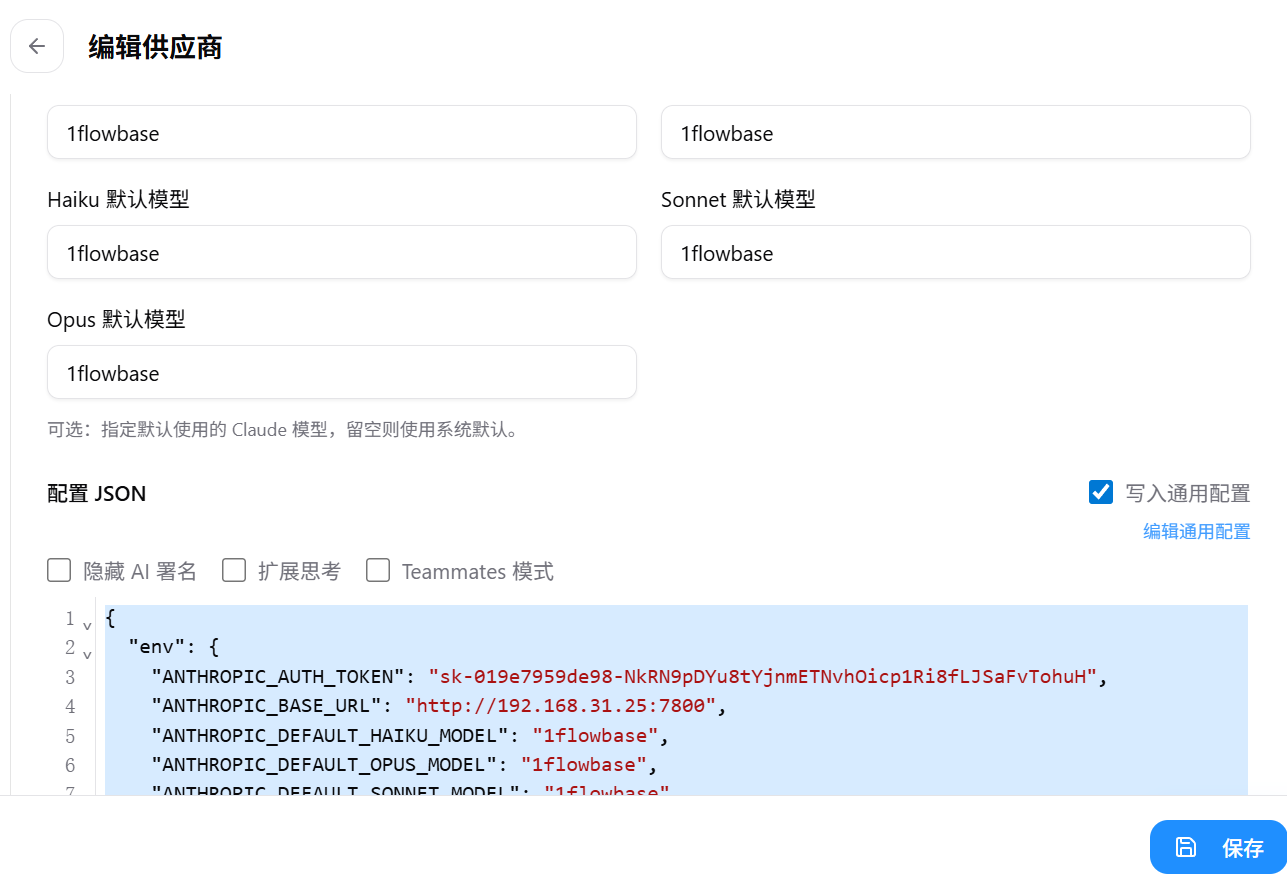
当然你可能会好奇,是不是模型id随便写都可以。
当然不是,你如果不配置,怎么知道模型上下文和压缩上限呢?
你需要在开始节点中配置对外提供模型信息:
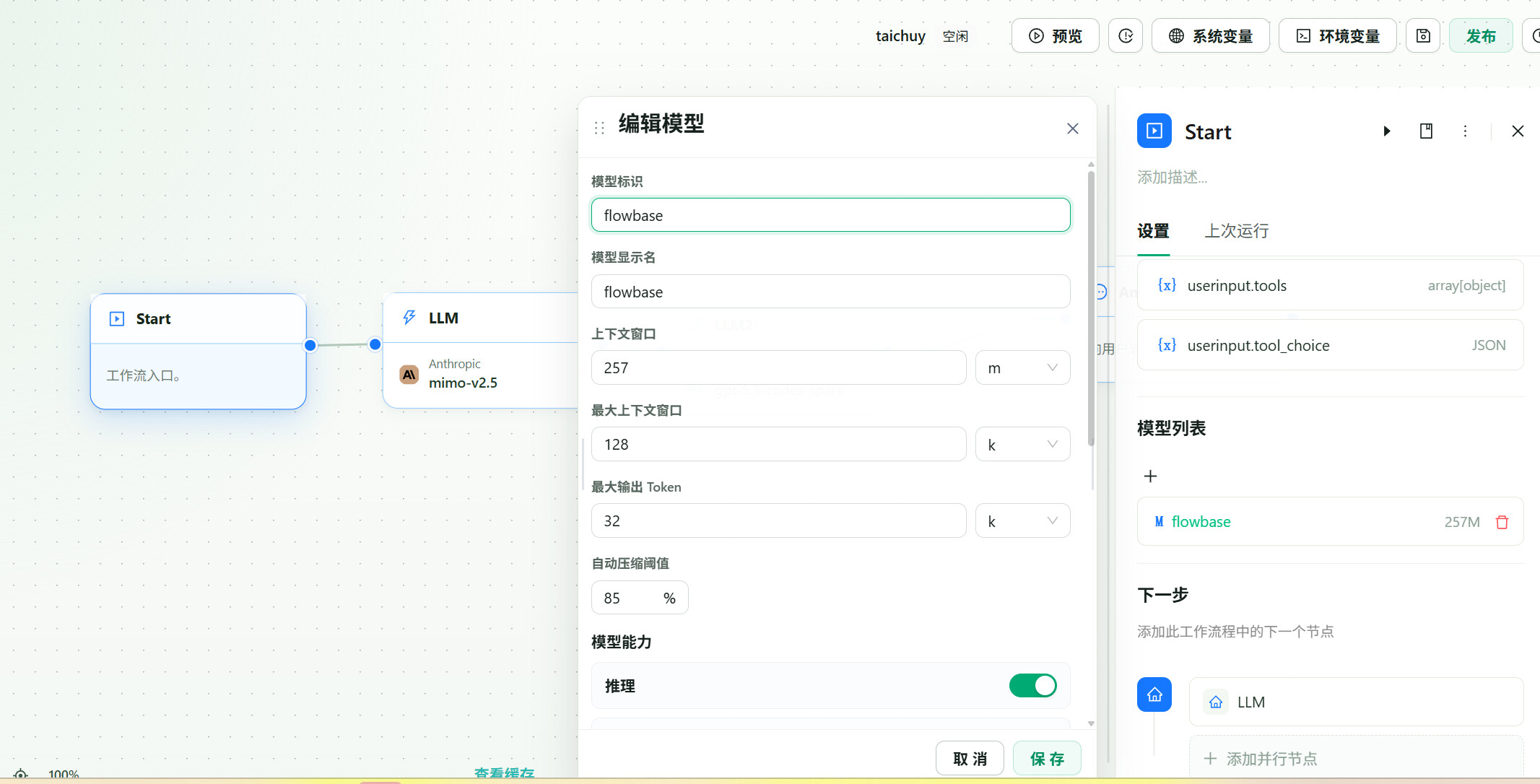
这样openai协议可以直接拉到模型上下文这些,anthropic 也可以知道上下文情况和协议情况。
然后你就可以直接在Claude code 对话使用
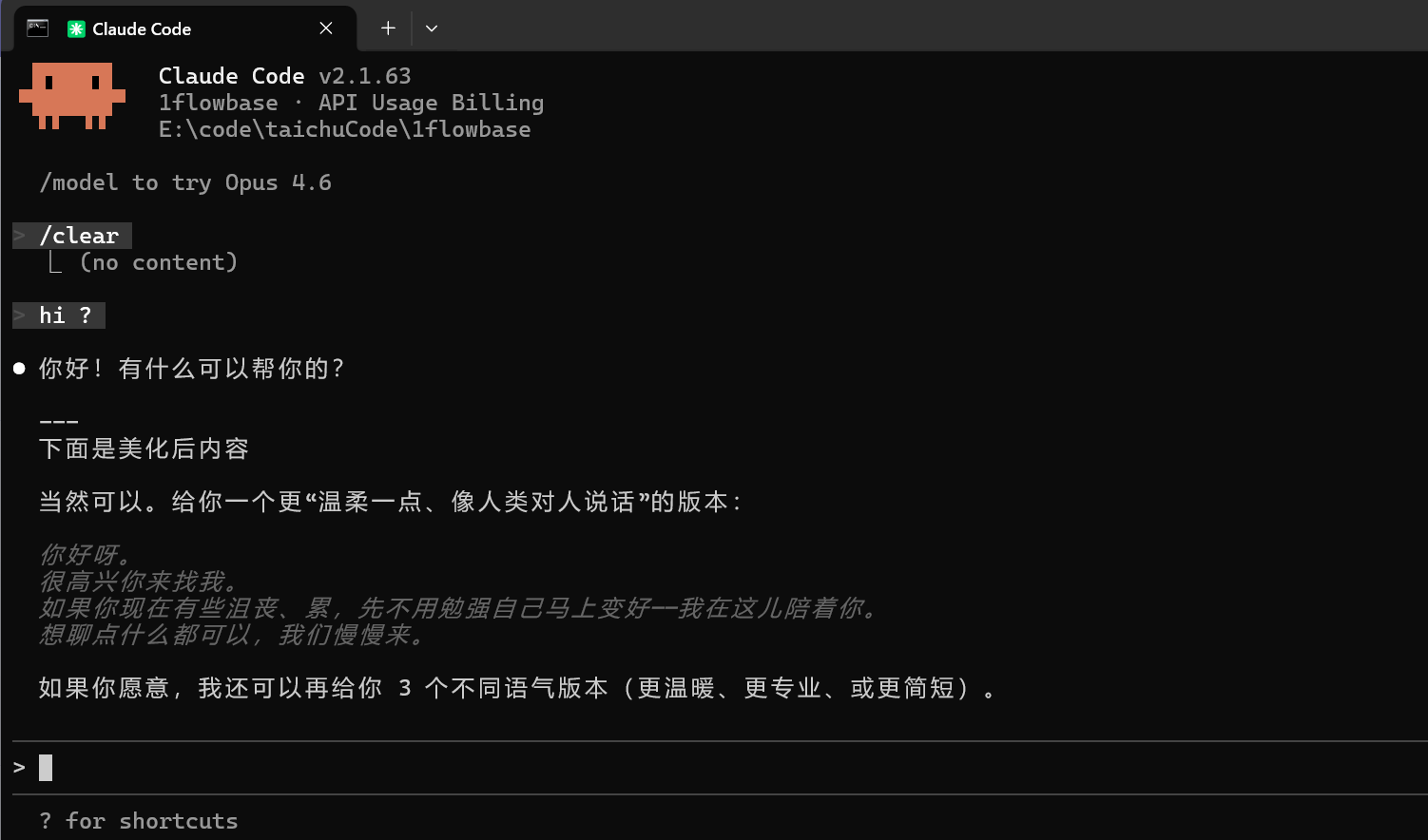
然后你就可以在日志中看到详细信息:
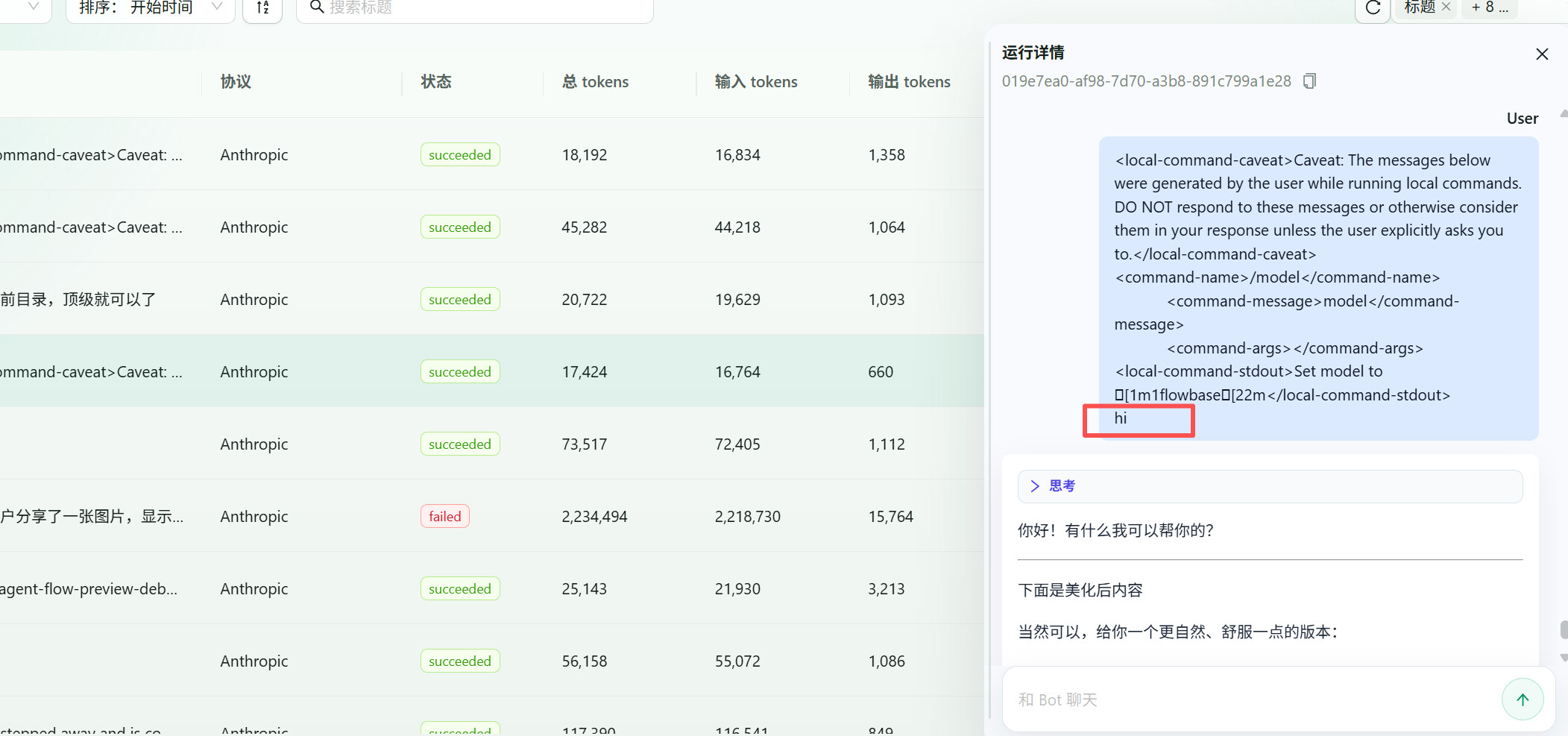
注意:"—下面美化内容"其实我手动组合回答:
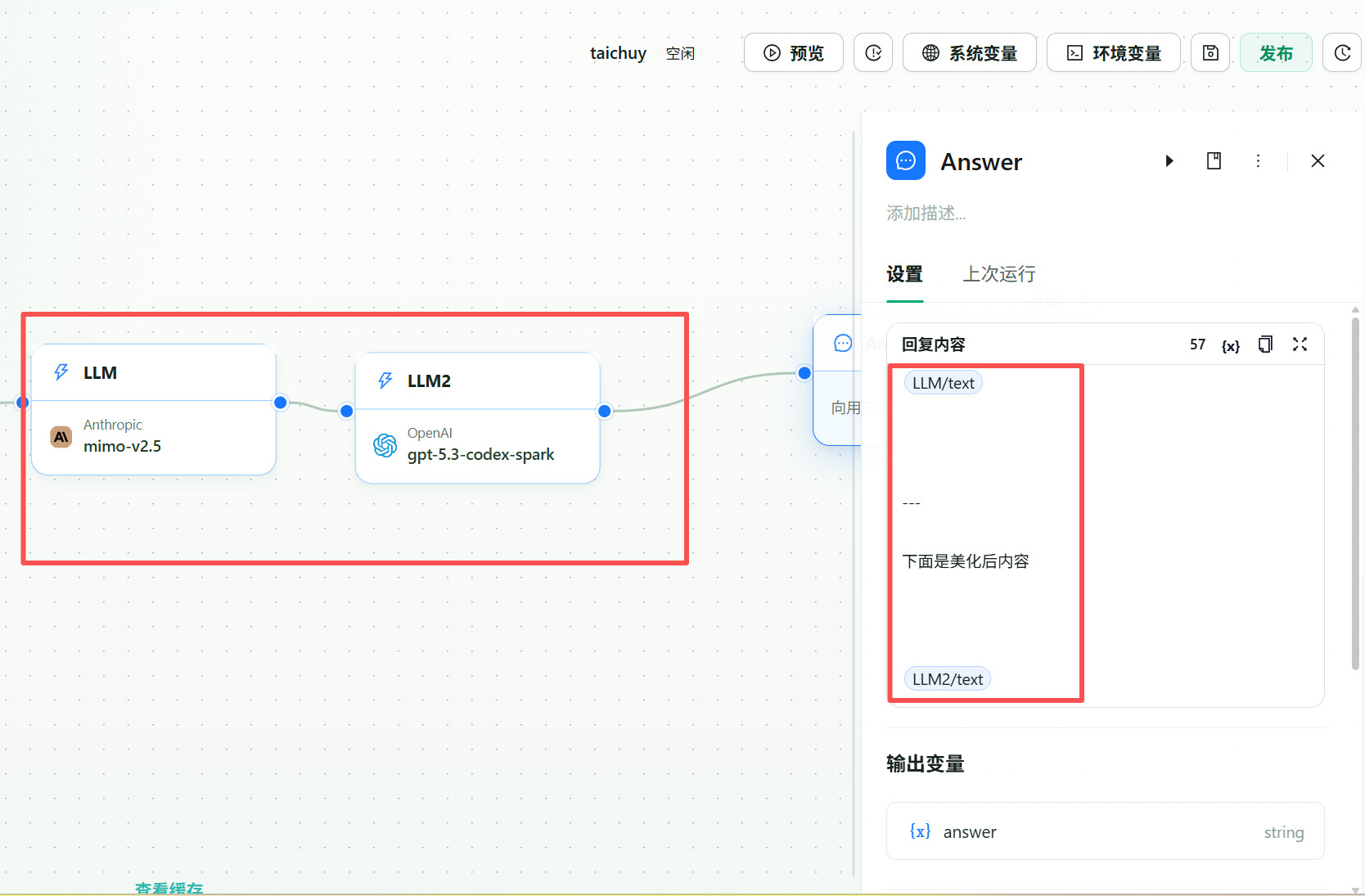
并且不仅仅回答,而是所有消息,比如说你可以看到Claude code 是如何拼接系统提示词:
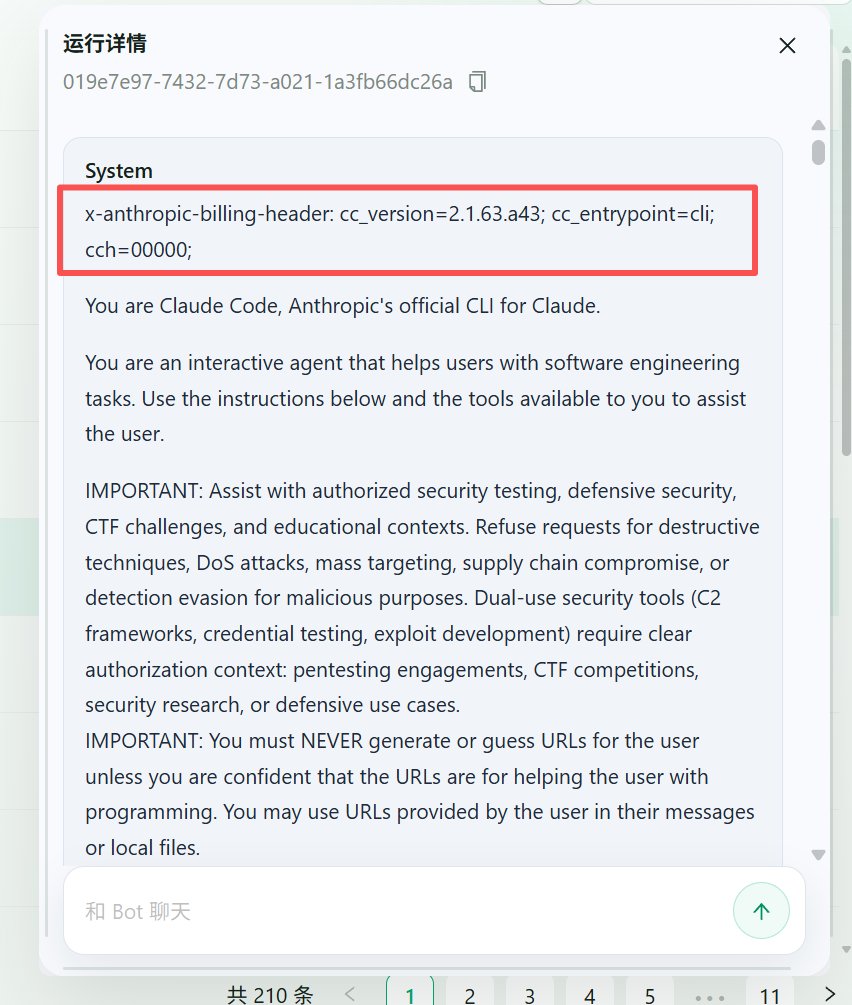
我们可以明显看到,Claude code 真的会向anthropic 服务器发送版本号这些信息。
如果是一个复杂任务,我们有详细回调日志:
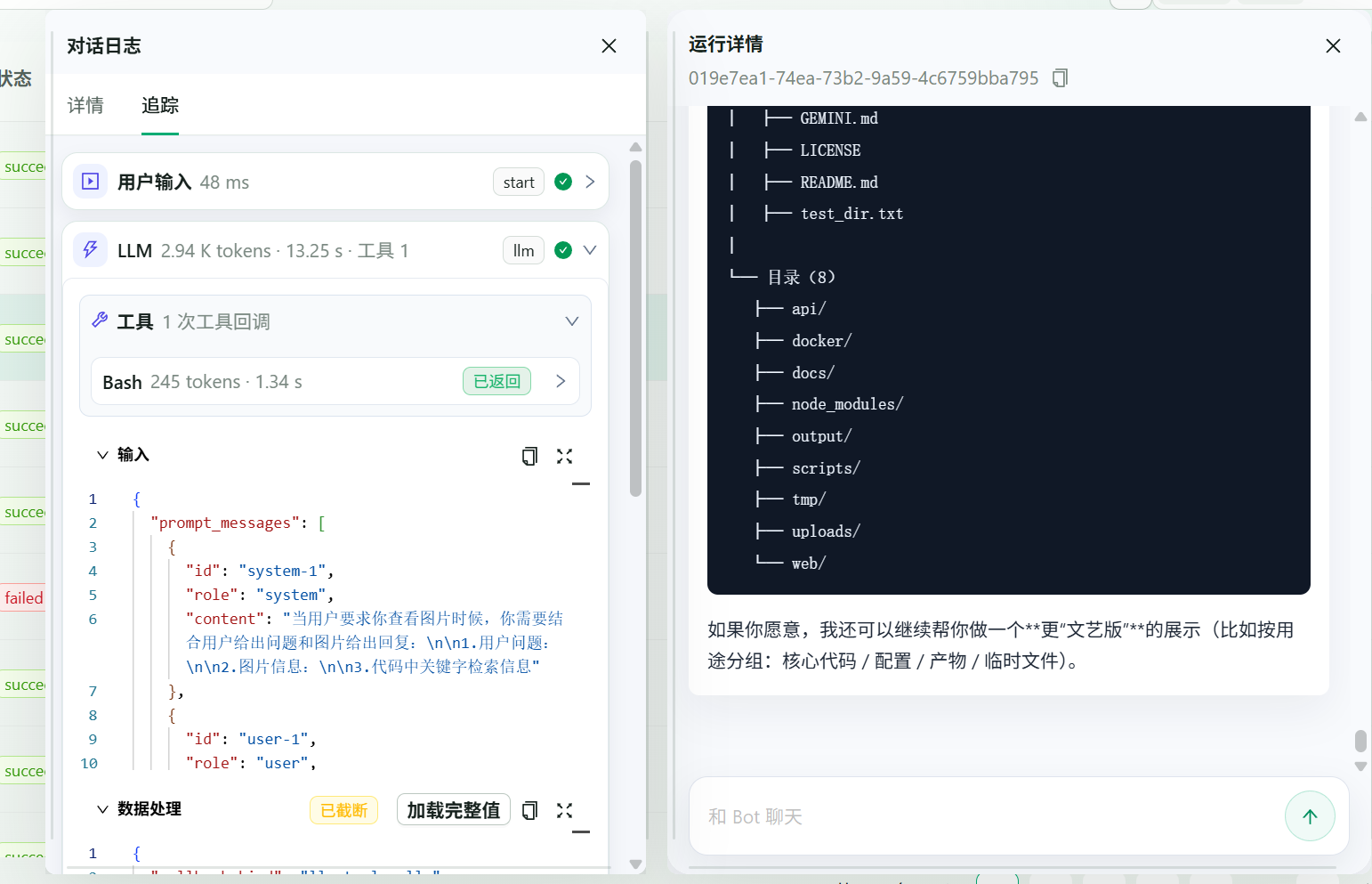
可以看清楚每一步消耗
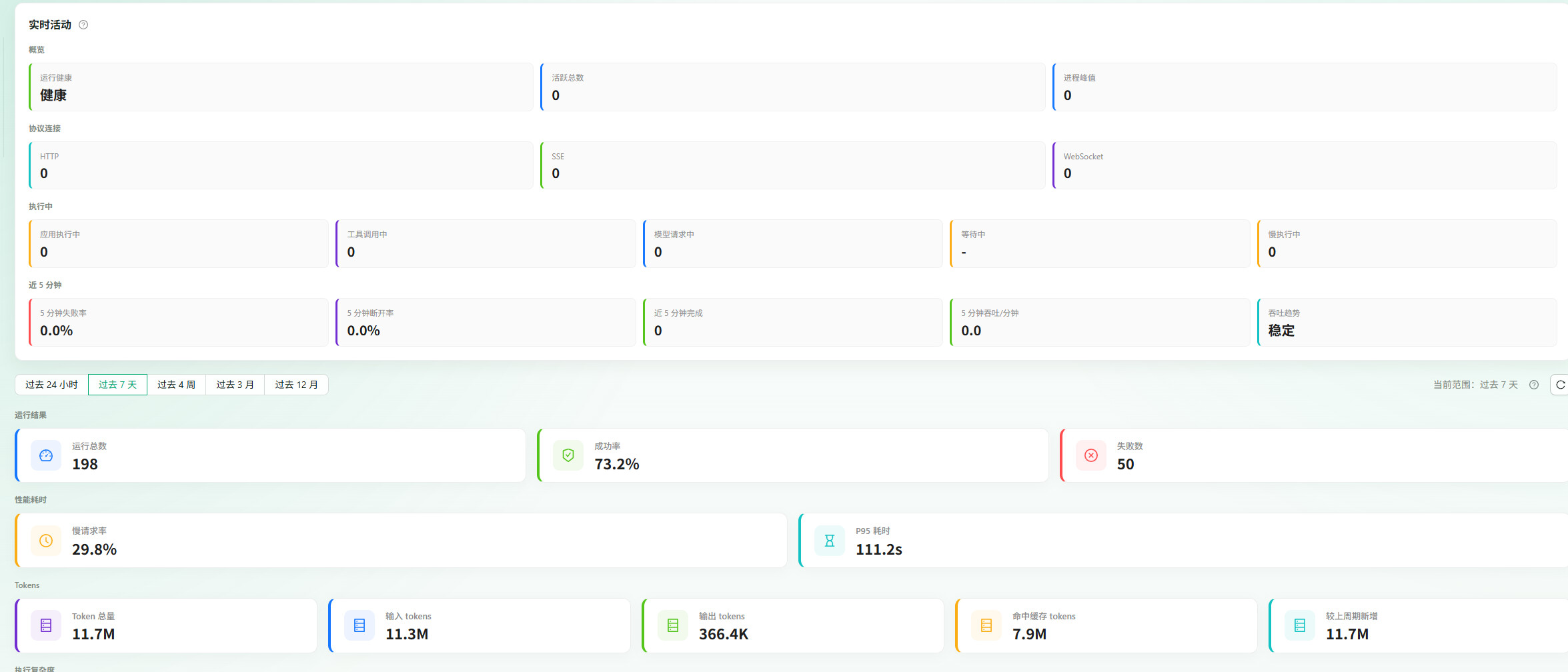
我们还有报表,统计每一个应用token消耗情况
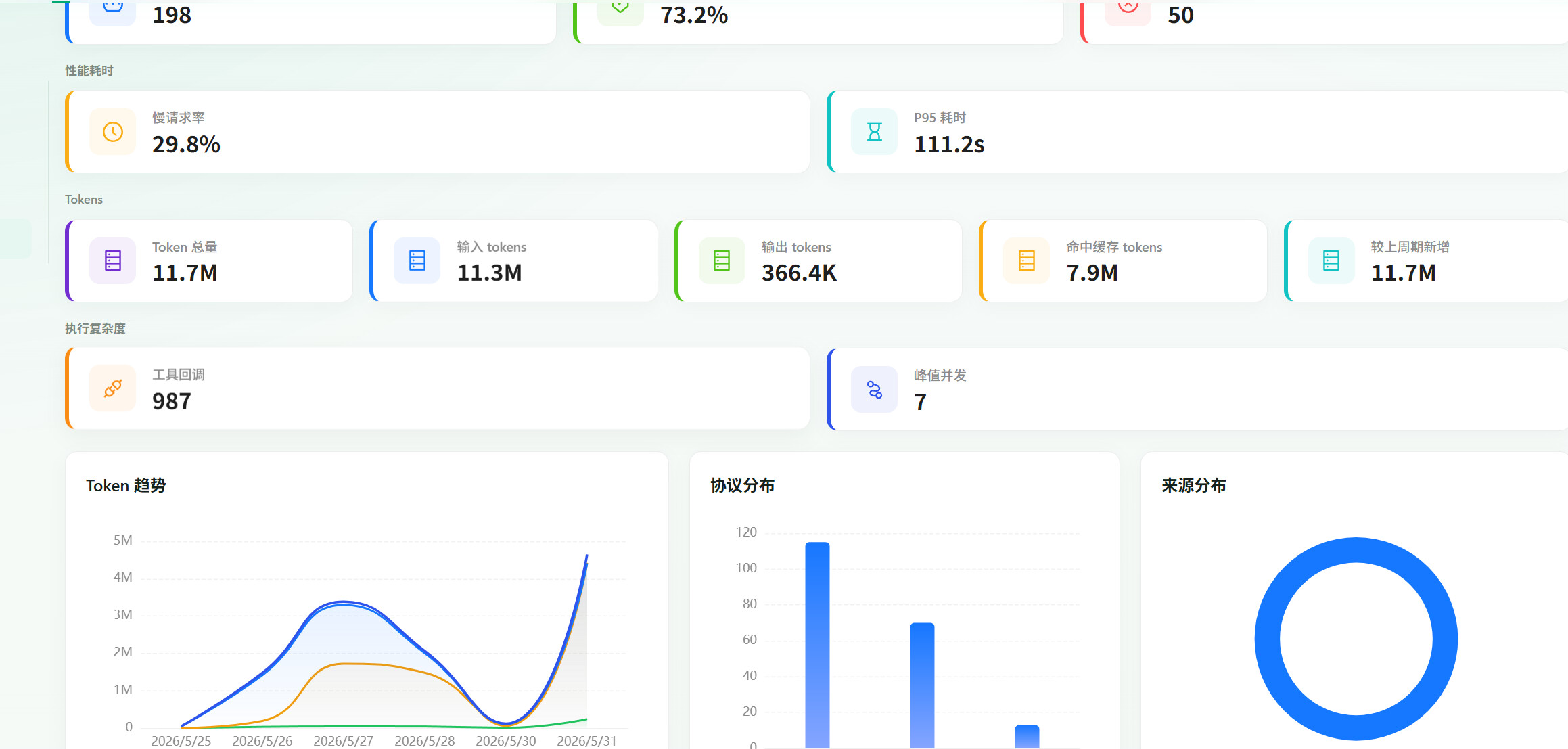

基本上好多都塞进去,因为我绝对界面可以慢慢调,但是数据一定要全,一言就能看到自己想要关注指标和数据。
这就是虚拟模型,可以任意组合分发发布对应为对应大模型接口,让个人和非大模型基座企业也能发布自己专属大模型。
发布大模型不在仅仅是openai,anthropic 这些基座模型权利,个人和企业能上桌吃饭了。
其他功能
这些就是全部了吗?当然不是,因为我们愿景不仅仅如此,我要做的是:

目前还在做功能,低代码,你可以在工作流中将对话或者其他中间产物存入数据库,然后快速创建页面查看。
定时任务:定时将最近聊天记录抽出来,整理归纳,甚至每天早上发一份日报告诉你昨天做了什么?有哪些可以改进,哪些要继续维持?
我们要构建是一流基础,所以你对于1flowbase 有什么改进建议意见,欢迎留言,私信,issue,当然也可以先点一个star观望一下。
项目地址:
github.com
GitHub - taichuy/1flowbase: Open-source AI gateway for publishing multi-model...
Open-source AI gateway for publishing multi-model workflows as OpenAI/Claude-compatible virtual model endpoints.
最后:
祝各位佬,儿童节快乐,今天是周一,也许很多佬已经将头发梳成大人模型在上班了,但是衷心希望你,有那么一段时间,可以什么都不想,做自己开心事情就好了,就像儿时的你一样
2 个帖子 - 2 位参与者