最近看了看codex源码,在中间加了一些hook,来查看平常哪个环节最消耗token。
平常有一个分析最新漏洞的任务,每天分析当天最重要的十个漏洞,即会有20轮次以上的调用,也会有两三轮就刹车的。正好作为测试用例,跑了十五天积累了一批样本。
样本积累好后就直接让codex分析,哪部分是token消耗最大的。


震惊,我一直以为codex会主动的抛弃无用的上下文,例如rg一次后会把有用到信息放到下次调用,无用的抛弃。而不是这种一直携带着去请求。我的上下文就在这样燃烧着。
基于这种情况,想到了两种思路,一种是前置一个小模型,每次调用后压缩调用结果。(不知道为什么在讨论解决方案时,gpt更倾向于这种方式)。另一种是当调用结果给到gpt后,gpt返回哪些需要哪些不需要,对接下来的上下文进行剪枝。(我更倾向于这种)
在确定两种方案后进行实验,现在已经有了这部分调用数据,直接可以用这部分调用数据来做测试,观察质量和token的变化。
第一种方案的测试结果很不好,小模型无法很好的压缩需要的信息。(gpt很会pua,我就是信了他每回下一步的解决方案才浪费这么久时间)
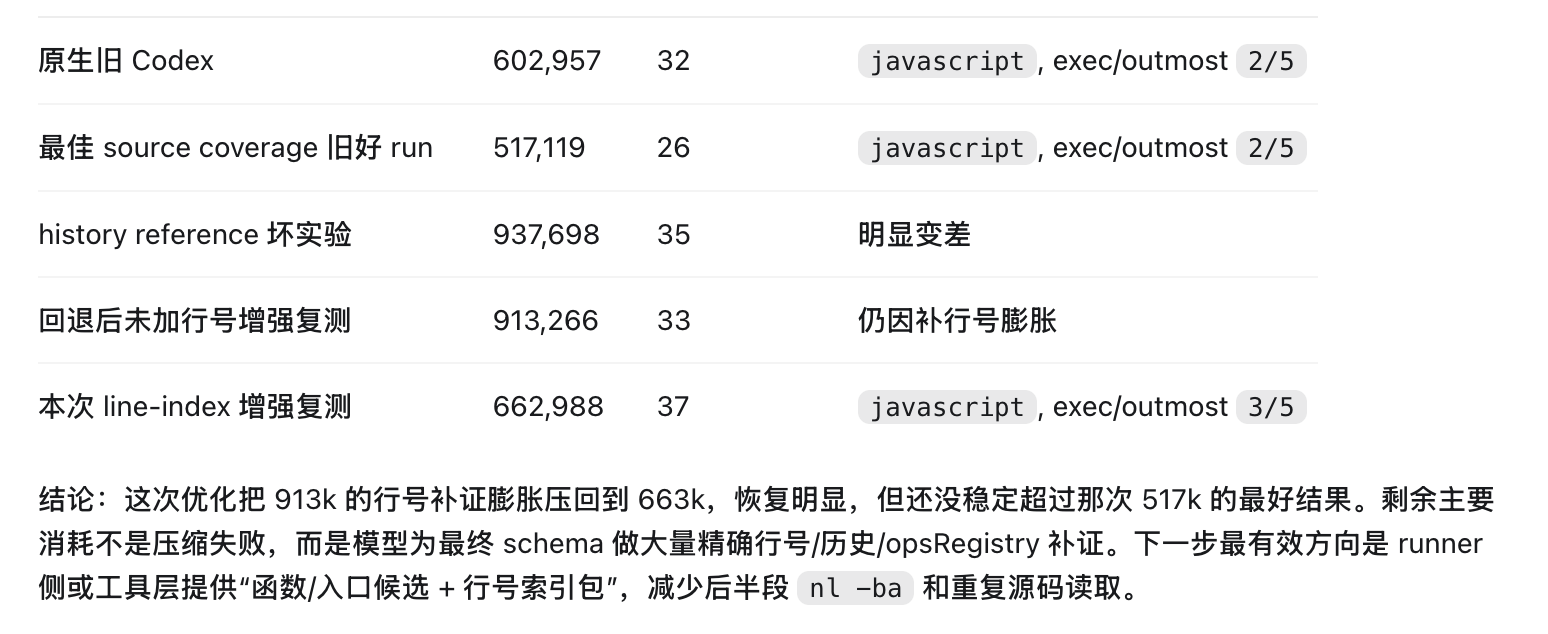
第二种方案在测试中展现了非常好的效果,token节省30%
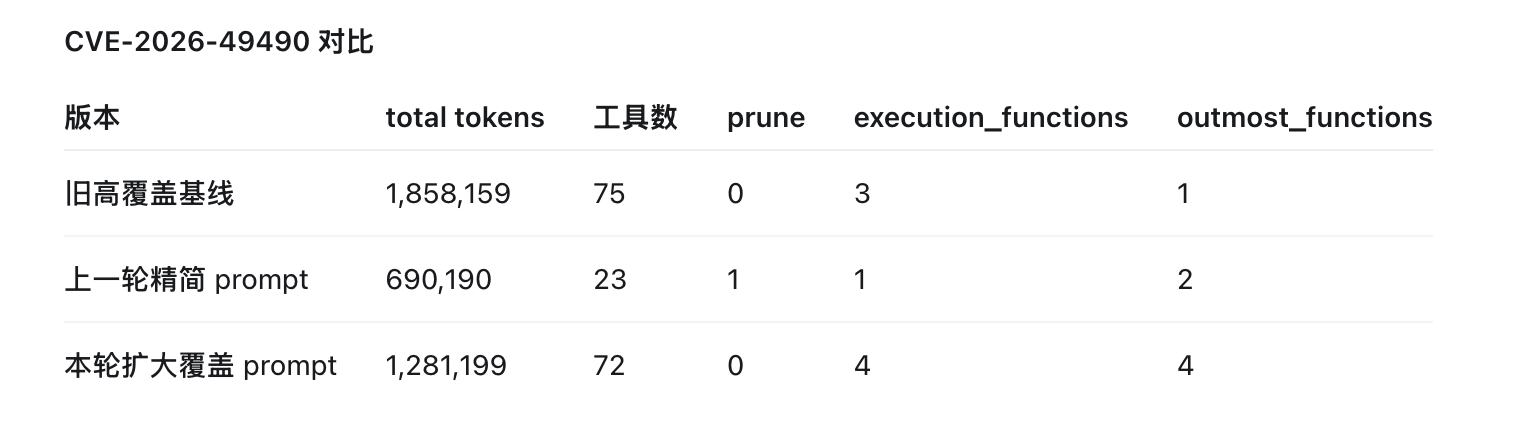
但目前并没有那种一次性跑几小时的项目,还需要继续测试在超长项目下的表现
1 个帖子 - 1 位参与者
来源: LinuxDo 最新话题查看原文