- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
github.com
GitHub - Dyalwayshappy/Spice: A decision brain for agentic systems: perceive...
A decision brain for agentic systems: perceive context, compare options, and control execution.
各位佬友好啊,我是Jia,一名有着9年coder经验的00后,同时也是 Spice 的创始人,前几篇帖子分别讲了 Spice 的起源与愿景,Runtime 的定位和落地以及区别于 Prompt engineering 和 Context engineering 的 State engineering,从这几个不同层面去介绍了 Spice 特别的地方和价值,感兴趣的佬友可以去翻一下我之前的几篇帖子,那今天我就来分享一下另一个有关 Agent Benchmark 的归因问题。
1. 试想一下
大家可以回想一下自己使用 Agent 时的情况,看看我说的这个现象在你的使用过程中有没有发生过:
你在使用 Hermes 的时候,输入了一个 task 例如:“帮我总结这篇文章,重点提炼作者的核心观点和反对观点”。Agent 开始执行,看起来过程很完整,他读了文章,整理结构,搜索相关资料并生成了一份报告,最后的结果也不是完全错的,但你发现他漏掉了很关键的反对观点的那部分。
这个时候你会怎么做?
大多数人的反应是重新输入一段新的指令让他再跑一遍,如果你发现漏掉了什么也会把提醒放在新的指令里。
表面上来看,这是一次非常普通的 refine 操作,但本质上用户是在帮助 Agent 做 decision feedback。 你在告诉他刚才结果哪里不对,哪个约束被忽略掉了,下一次该关注什么。
然而这种反馈通常只留在了下一轮的 prompt 里(即你新的输入),它不一定会被系统稳定记录,也完全不会变成后续类似任务可参考的决策依据。
这是一个很简单的例子,在更复杂的任务这个问题会被无限放大,Agent 执行的结果不符合你的预期,归因是一件非常困难的事情,大家除了写新的指令重新执行一遍这种方法,最常见的就是找另一个 Agent 去进行 review,但仍然还是治标不治本。
2. Agent的能力评估标准
这个现象不止发生在我们的日常使用中,很多 Agent benchmark 其实也是用类似方式评估能力:给 Agent 一个任务,然后看最终结果是否成功。
例如 SWE - bench 是验证 AI 能不能根据真实 Github issue 生成 patch, 并用 resolved / pass tset 来判断是否解决问题; WebArena 看 Agent 能不能在网页环境里完成任务,并用程序验证最终功能正确性; OSWorld 看 Agent 在真实桌面环境里执行任务后的最终状态是否满足要求;GAIA 看多步工具使用后最终答案是否正确。
这些 benchmark 都是非常重要的衡量标准,但它们大多还是在用最终 result 反推 Agent 能力。 任务完成了说明这个 Agent 能力很强, 任务失败了证明这个 Agent 还有待提高。
3. 半年前的经历
这里有一个小小的故事,我自己对这个问题的感受很深,是因为去年我做过一个 coding agent 产品。
那个项目有点像一个 full-stack 版的 Lovable。我们的目标是把 Web 开发变成一种搭积木的过程:把 Google Login、Stripe Payment、数据库、用户系统、页面模板等常见能力做成模块,再让 Agent 基于我们写好的 blueprint,在具体项目里进行个性化填充。
当时这个思路看起来很清晰,我们想做成 developer 领域的拓竹:既然模块和 blueprint 都已经固定了,Agent 要做的似乎只是根据用户需求把这些模块组合起来、补齐细节。
真正跑起来以后,我们发现一个很明显的问题:即使是同一个 blueprint、同一个模块、同一个用户需求,不同 LLM 或不同轮次生成出来的结果稳定性也很差。有时候它会正确理解 blueprint 的边界,有时候会擅自改模块结构;有时候会把 Google Login 接到正确的 auth flow 里,有时候会绕过我们设计好的抽象,这里所有的不稳定性我们都无法归因。
到底是没有理解用户 intent?还是 blueprint 设计不清楚?是 context 没给够?是模块能力本身不完整?还是 executor 在具体代码生成时跑偏了?
我们唯一能做的就是通过大量的 test 去调整整个链路,这是一个相当折磨的过程(大量的tokens消耗以及时间)
4. Spice 想评估的其实是 Decision
一个 Agent 做错,可能不是他的 tool call 能力或执行能力不行,而是 decision 出错了,它一开始就选错了方向,忽略了某个约束,错误判断了哪个信息更重要,或者没有把上一轮失败反馈进下一次决策。
这也是我在做 Spice 之前的一个判断,我们应该通过追溯到 Agent “它当时为什么做了这个选择”,来优化 Agent 的能力本身。
一次 Agent 任务中,其实有很多 decision 点:
- 它为什么认为这个信息是关键?
- 它为什么选择搜索,而不是直接阅读原文?
- 它为什么把某个观点放进总结,而忽略了另一个观点?
- 它为什么选择继续执行,而不是停下来向用户确认?
- 它为什么把这次失败归因成 context 不够,而不是 intent 理解错了?
现在这些 decision 都发生在黑盒中,在 LLM 的隐式推理中,用户最后只能看到 result,看到一些 tool log 或执行轨迹。很难知道每个关键选择背后的依据是什么,这也导致了我们的归因困难。
Spice 想做的是把这些 decision 显式化,在 Spice 里,一次任务不应该只有 final result,还应该有一条 decision trace:
intent / signal
-> observation
-> state
-> candidate decisions
-> comparison
-> selected decision
-> execution
-> outcome feedback
当结果不符合预期时,我们不只是重新 prompt 一遍,而是可以回头审计过程:
- 是 observation 提取错了?
- 是 state 里缺少关键约束?
- 是 candidate decision 生成得不够好?
- 是比较时忽略了用户偏好?
- 是 executor 执行失败?
- 还是 outcome feedback 没有被写回系统?
所以我现在更倾向于把 Agent 的问题拆成两层:
execution quality and decision quality
execution quality 评估"执行结果",decision quality 评估的是"它为什么这样做,以及这个选择是否可以被复盘、纠正和复用"。
Spice 的诞生就是我们实现这一目标的开始。
5. Decision Card:让 Agent 的决策过程可以被复盘
在 Spice 里,我希望每一次 Agent 执行之前,都不只是生成一个 task 或者 todo list,而是先生成一个 Decision Card
Decision Card 是为了把每次的 decision 显式记录下来,他包含:
- 当前 intent / signal 是什么
- 系统观察到了什么 observation
- 当前 state 里有哪些相关约束
- 有哪些 candidate decisions
- 每个 candidate 的依据和风险是什么
- 最后为什么选择了这个 decision
- 是否需要用户 approval
- 交给了哪个 executor
- executor 返回了什么 outcome
- 这次 outcome 应该如何反馈到下一次 decision
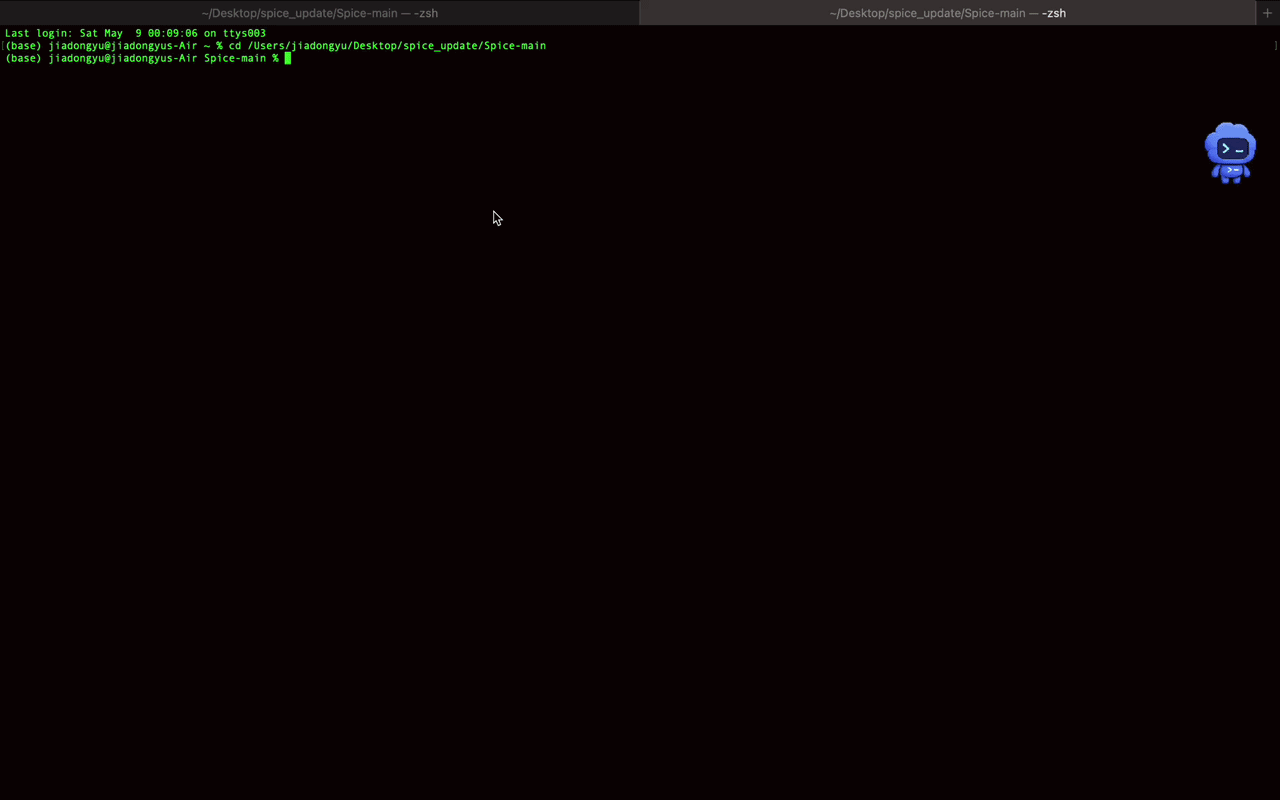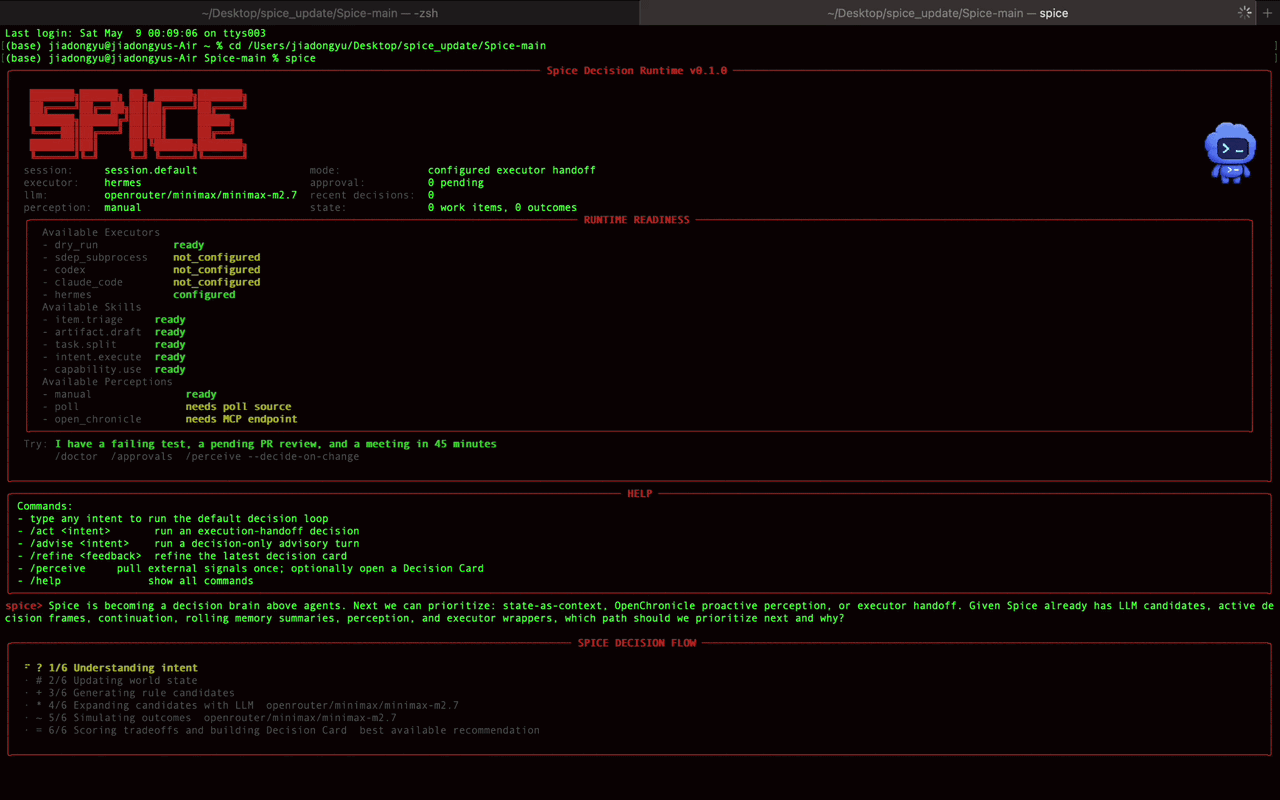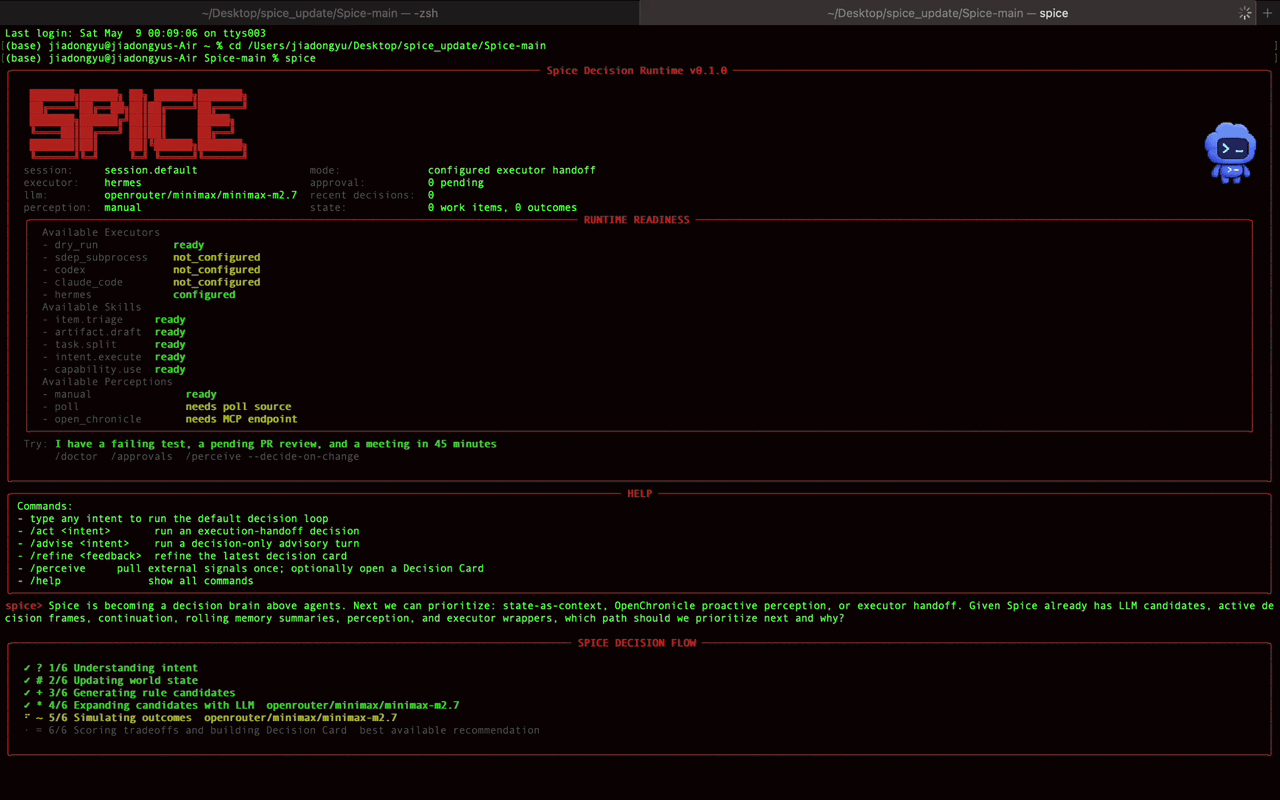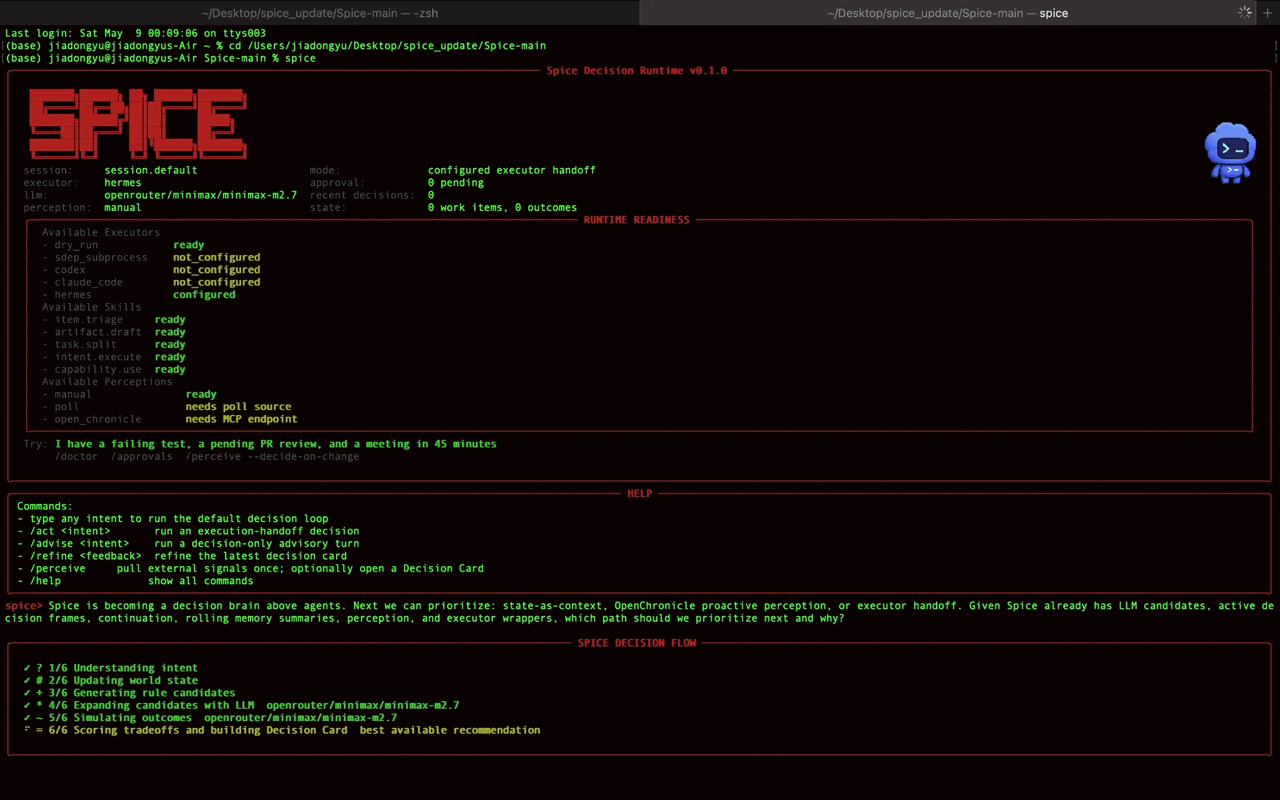
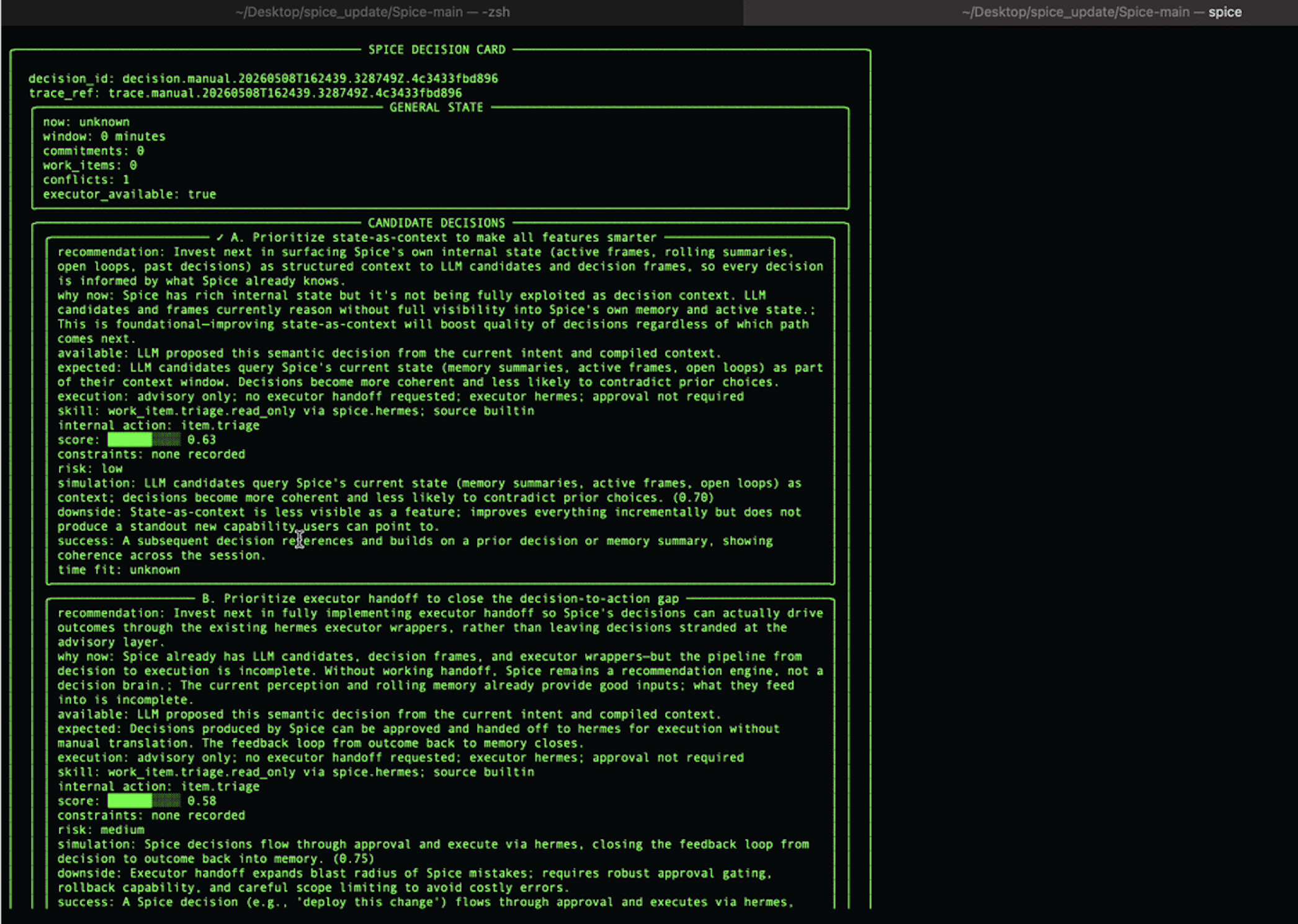
这样做的好处是,当 Agent 最后结果不符合预期时,我们不只能说"它又跑偏了",而是可以回到 decision trace 里看问题出在哪里,是没理解 intent 还是 context 本身有问题。
很多 Agent evolution 还是在沉淀执行能力,在执行能力上自进化,而 Spice 的诞生就是 result evaluation 和 decision evaluation 的区别。
Result evaluation 只看最终有没有做成;Decision evaluation 看的是:这个 Agent 当时为什么这样做,这个选择是否合理,以及失败之后系统能不能从这次选择中学到东西。
这类 decision trace 未来可以变成一种新的 Agent eval artifact。
今天很多 benchmark 记录的是任务输入和最终输出,最多加上 tool trace。但如果我们想评估一个长期 Agent,只看 final result 可能不够。我们还需要看它在过程中做了哪些关键 decision,是否正确使用了 state,是否考虑了约束,是否能把 outcome feedback 写回下一次决策。
6. Spice 的下一步:从 Runtime 到 Benchmark
这也是 Spice 发展的下一步方向,现在的 Spice 还是一个 runtime,大家可以快速的 setup,在自己的不同领域使用,让你的每次交互都变得清晰,让过程可审计,可回溯,更好的归因。
如果我们真的认为 Agent 不应该只评估 final result,而应该评估 decision quality,那下一步就需要把这件事做成可复现的 benchmark。
我们想逐步建立一套围绕 decision trace 的评估方式:不只是看任务有没有完成,而是看一次 Agent 执行过程中的关键 decision 是否合理,是否考虑了正确的 state 和约束,是否选择了合适的 executor,是否能在失败后进行正确归因,并把 outcome 反馈到后续决策里。
这类 benchmark 和现有 benchmark 不太一样。它不一定只给一个 task,然后看最终答案是否正确;它更关注任务过程中的 decision path:
- 是否识别出关键 observation
- 是否保留了合理的 candidate decisions
- 是否解释了为什么选择 A 而不是 B
- 是否在高风险行为前触发 approval
- 是否能区分 decision failure 和 execution failure
- 是否能把失败结果写回下一次 decision
如果说现有 benchmark 更多是在问"Agent 最后做成了吗",那 Spice 想继续追问的是:“它为什么这样做,以及下一次能不能做得更好?”
我们也希望在这个过程中,把 Spice 从一个开源 runtime,逐步推进成一个可以被研究、复现、比较的 decision layer framework。后面如果这套 benchmark 和方法论足够成熟,我们也会整理成 paper,把 Agent decision quality 这件事更系统地讲清楚。
7. 写在最后
这段时间每发一篇分享就会听到有很多佬友在不同的领域使用 Spice,给我们更多的反馈和认可,和我探讨更多的技术问题,我深深的感受到了大家的热情。
Spice 还处于早期,我们的发展离不开大家的帮助,如果觉得我的分享对你有启发,或是有不同观点,欢迎来评论区讨论或者通过 Github 联系我,希望感兴趣的各位能帮 Spice 点个 star ![]() ,如果试用一下 Spice 那就再好不过了,总之我还会持续分析我的一些技术见解,还会有一些对未来的思考,希望大家多多支持!
,如果试用一下 Spice 那就再好不过了,总之我还会持续分析我的一些技术见解,还会有一些对未来的思考,希望大家多多支持!
1 个帖子 - 1 位参与者