- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
AIGC已经截图,github在readme添加了linux do友链
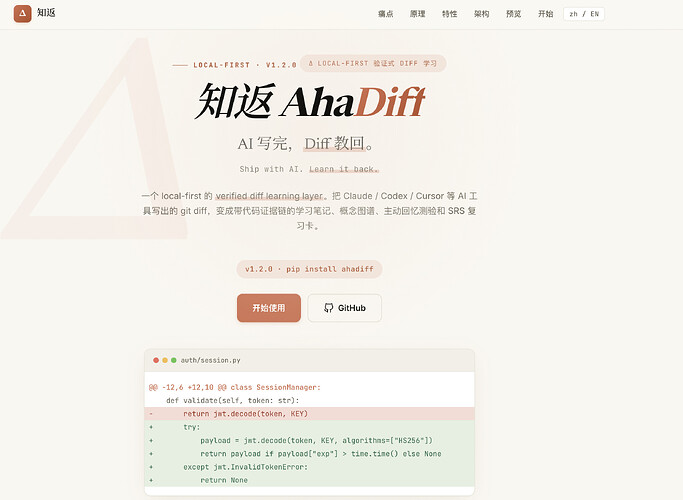
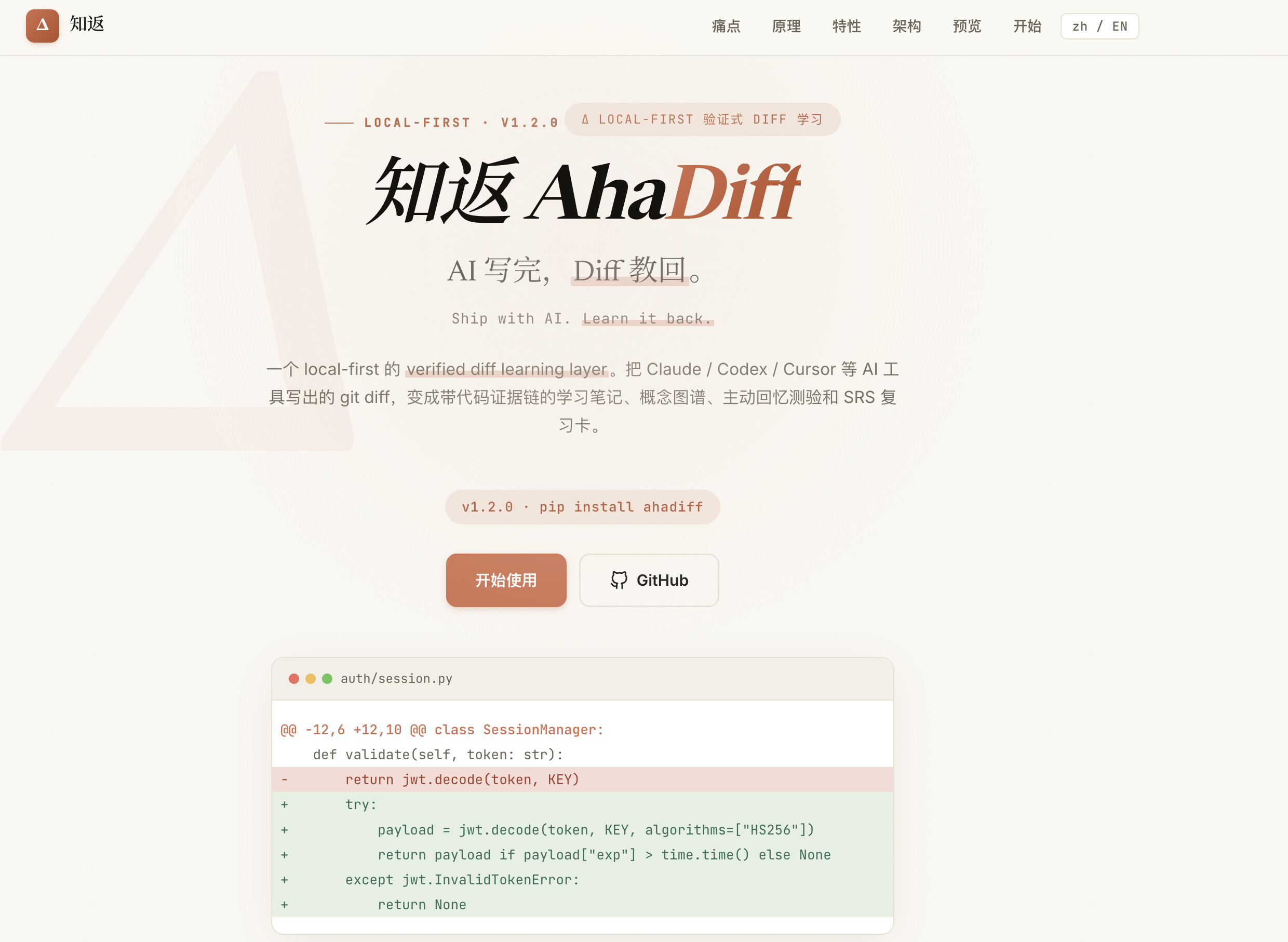
vibe coding 之后,你真的学到东西了吗?
一个开源工具「知返 AhaDiff」:把 AI 写的每次改动都给你讲清楚,让你vibe coding时不再无脑点继续的,从中学到真东西。
起因:使用ai进行vibe coding虽然快,但是代码中的改动却没有内化成自己的知识
我用 AI 写代码经常是这样:给ai相关需求,用ai写出一大段代码。我大致扫一眼,感觉没啥问题,就继续下去了;只要没出错就一直继续。
如果报错或者不符合我的需求就把问题告诉ai,进行改动。项目完成了,各个功能都正常运行了,跑得也不错。
可是有个问题,假如你回头问我「这个地方为什么这么写」,很大可能是一脸懵逼的状态,因为ai替我完成了90%以上的代码改动。
并且在论坛中我经常看到类似的讨论,很多人都提及了这个问题:通过vibe coding指挥AI把活干了,效率确实高,可一个项目做完,自己好像没怎么长进,没有从中学到真东西。
我想要的其实很简单:AI 写完之后,有个东西能把这次改动给我讲清楚,为什么要这么改,这么改的作用何在,并且把这次改动的知识进行内化,形成自己脑子中的知识,于是就开发了知返这个项目。
它就干一件事:把ai的改动变成能查证的笔记,能让你学到真知识
知返通过读你的一次代码改动,把它变成一份完整的学习材料:形成一篇完整的「改了什么、为什么这样修改」的课程,一份每条结论都标了出处的清单。同时附带完善的测验和带复习周期的复习卡片,通过复习曲线设置,一遍遍的重复,避免相关知识的遗忘,而不仅仅只是展现相关改动的相关知识点。
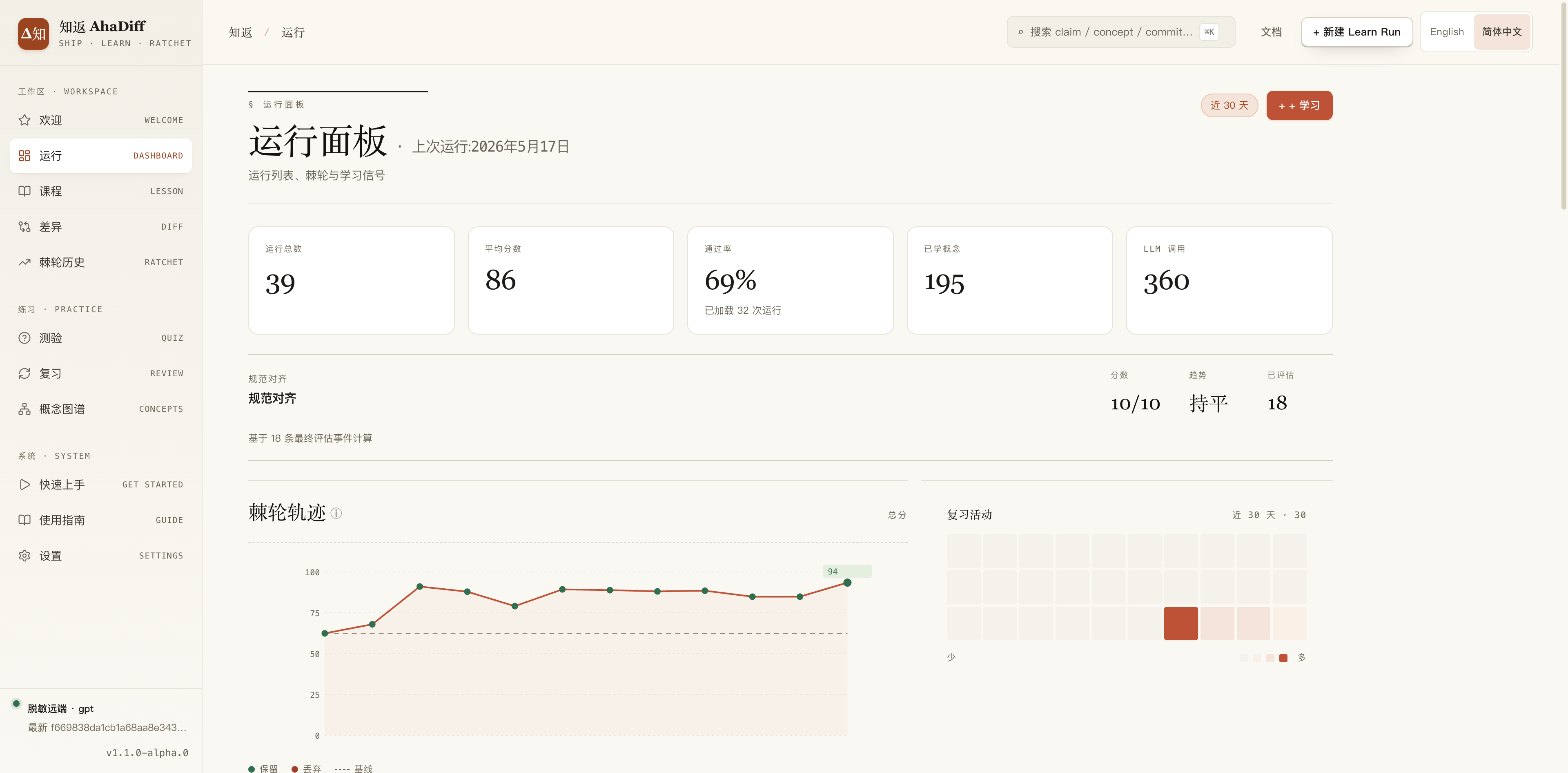
运行面板:每学一次就多一条记录,带评分和质量趋势
并且为了避免ai的幻觉问题:笔记里每一句话,都要绑到某个文件的某一行代码上,再附带这个学习笔记对应的一个状态:
-
verified有据可查 -
weak证据偏弱 -
not_proven没验证到 -
contradicted和代码对不上 -
rejected被否决
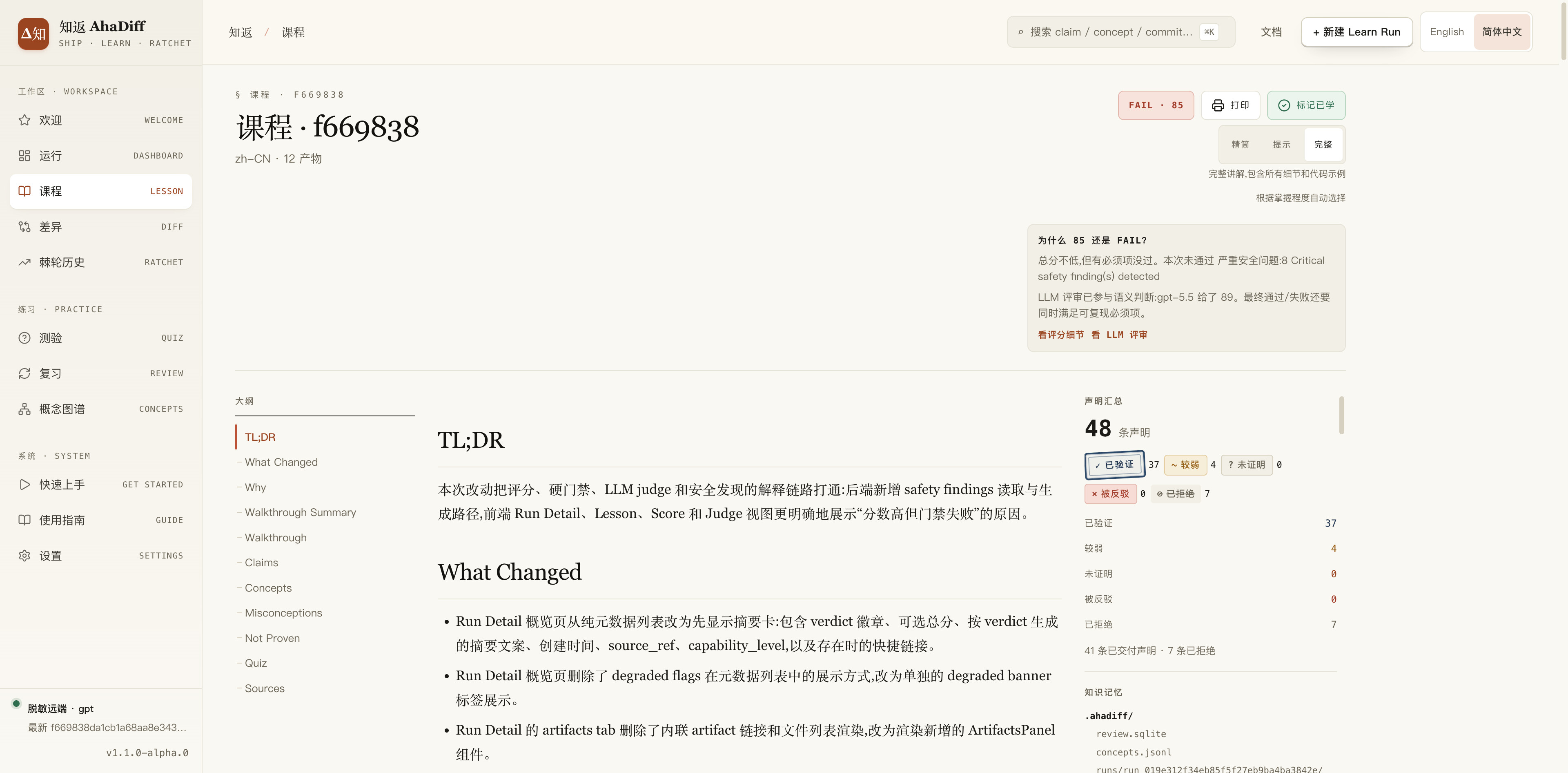
课程页:AI 把这次改动的相关知识点展现给你看
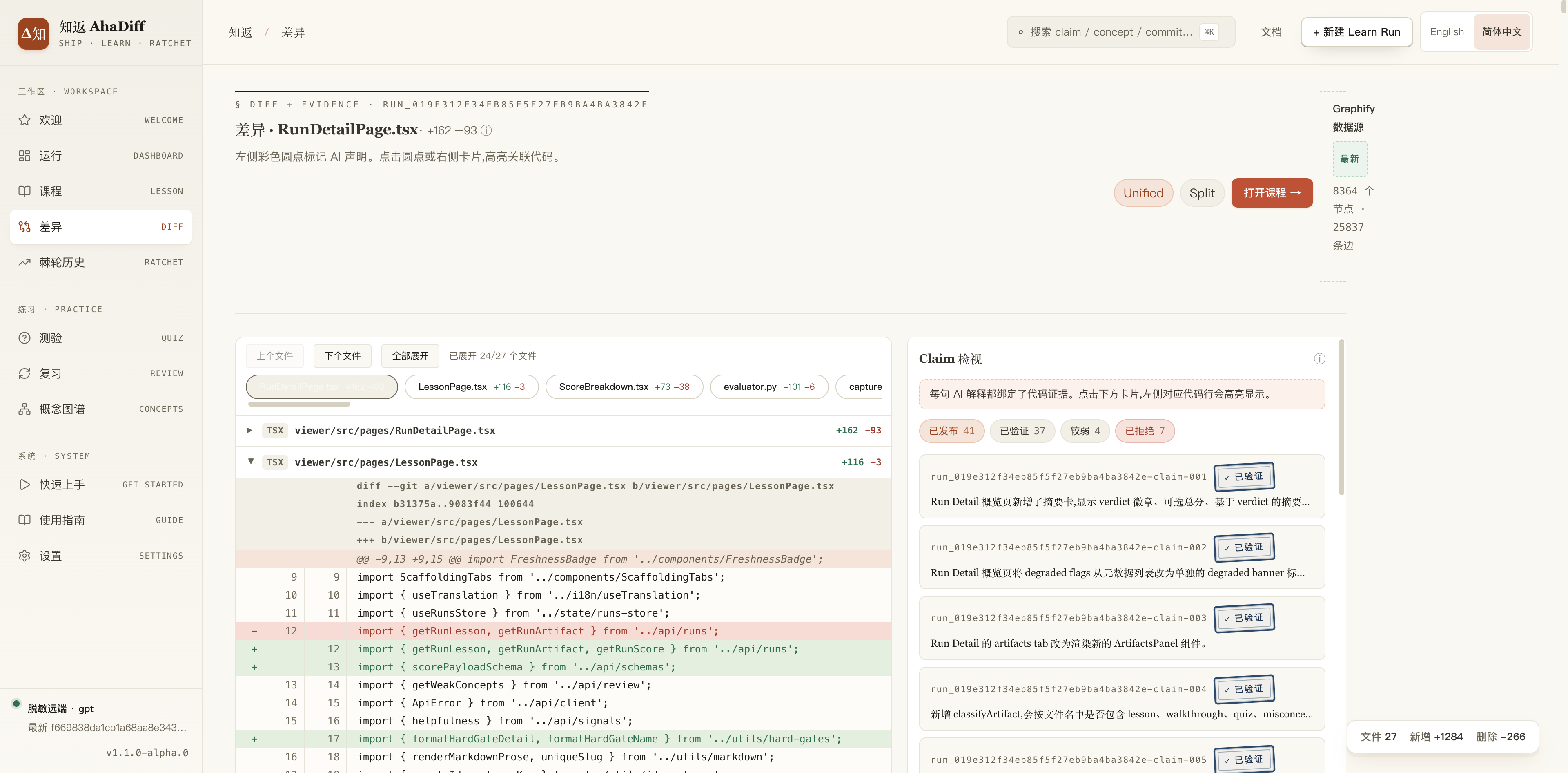
差异页:左边是代码diff,右侧的claim卡片点开,会跳转到对应diff,同时能看到这次改动对应的知识点
光看知识点还不够,那么我们学习完成之后测试你真的会了吗,并且根据fsrs算法,会加入之前做过的测验题
看懂了lesson的笔记知识点,不代表你真的会了,并且会用了,所以学习完课程之后还附带了测验和复习卡片。
测验是 通过选择题的方式呈现给你,可在settings中动态设置测验题的数量。
每道题答题完成之后,能看这道题对应的知识点,以及这道题经常出错的地方
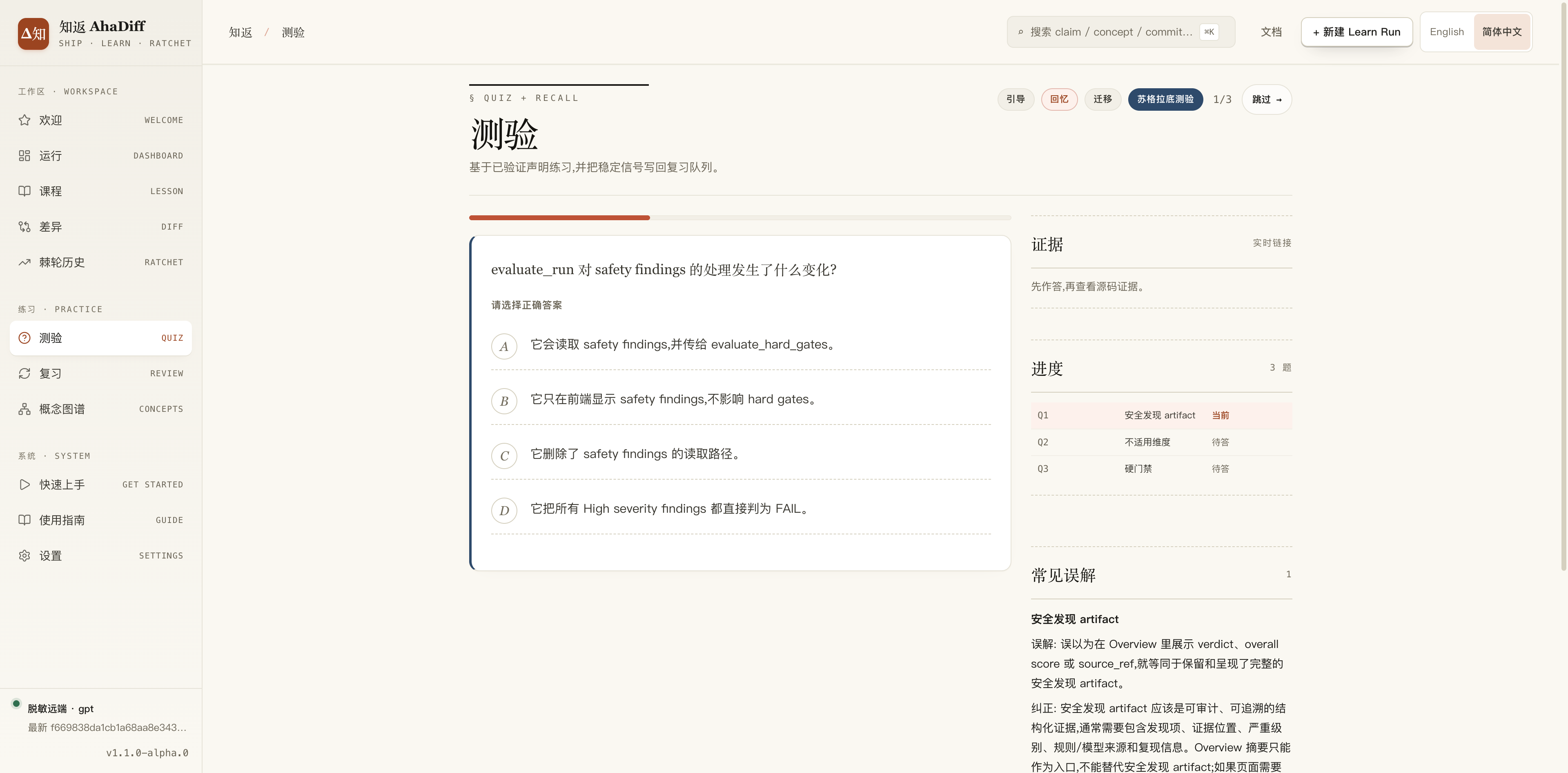
测验页:以选择题的形式呈现,答完才显示这道题目对应的代码改动
复习用的是间隔重复,就是 Anki 复习卡片那套思路,背后是 FSRS 算法。学过的东西会按遗忘曲线,在合适的时间点加入到复习部分让你再过一遍,避免看一遍就忘的情况。
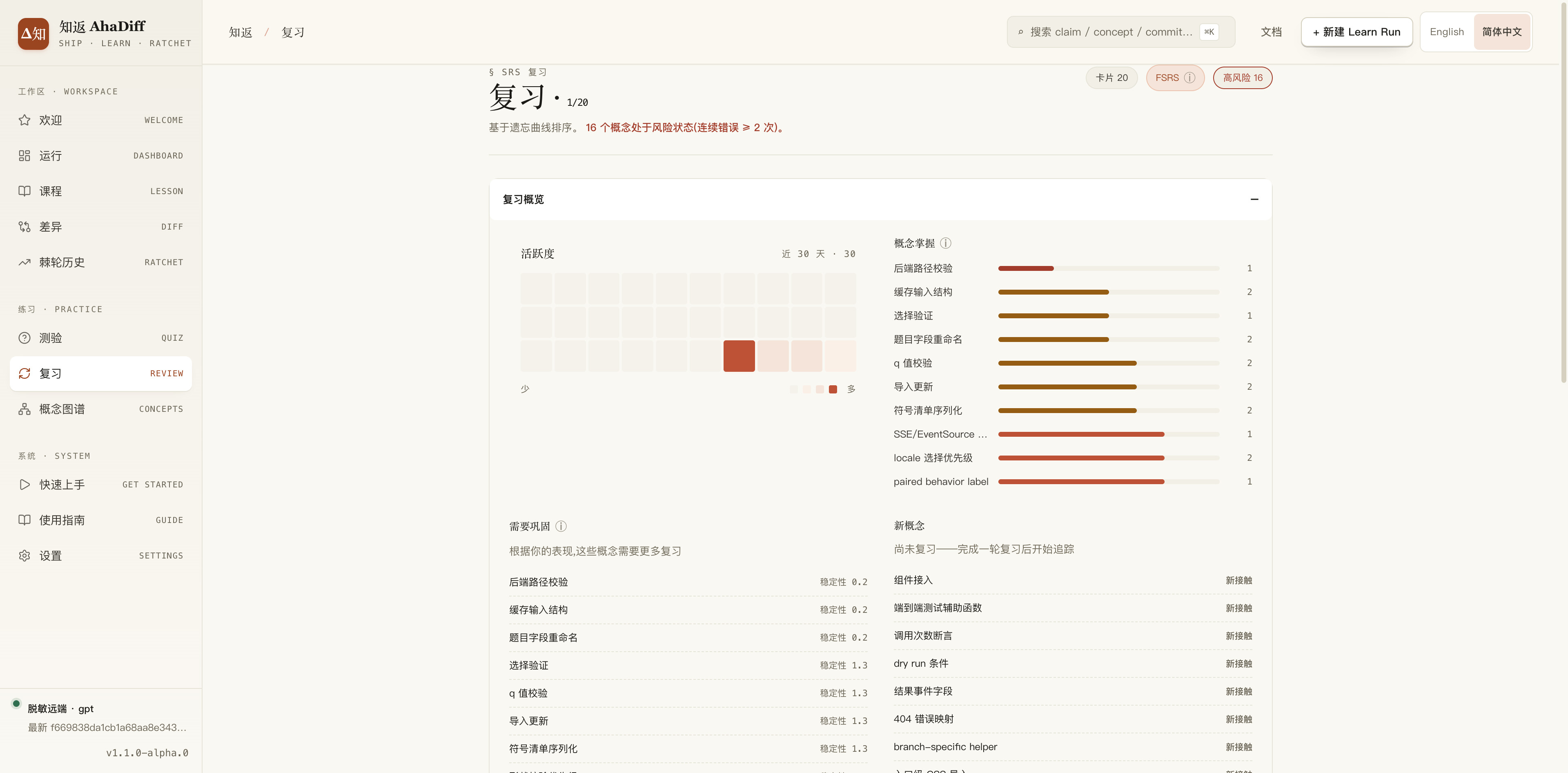
复习页:到期的卡片按 Again / Hard / Good / Easy 评分
测验和复习还嫌不够的话,再来个 Challenge(opt-in 的进阶玩法):它把某次改动做成一道挑战,让你自己先过一遍,再拿你的结果和真实 diff 逐条比对,把你漏掉、没掌握的地方挑出来,然后反馈到复习中。对着某个 run id 跑 ahadiff challenge build <run_id>,就能在webui中体现。
学得多了,知识会自己连成网,形成真正的概念图谱
借鉴了llm-wiki和graphify的思路。
同一个概念在好几次改动里反复出现,知返会把它们收集起来,连成一张概念图谱。
概念图谱:横跨多次改动的知识地图
每次学习都打分,能看出自己在不在进步
每跑一次,知返会从准确性、证据、覆盖率等八个维度打个 0 到 100 的分,判定这次课程学习算不算合格。你也可以设置不同的模型当「第二评委」复核一遍,避免同一个模型有没有考虑到的地方。
课程分数是透明的,点开能看到每一个维度的评分细节。
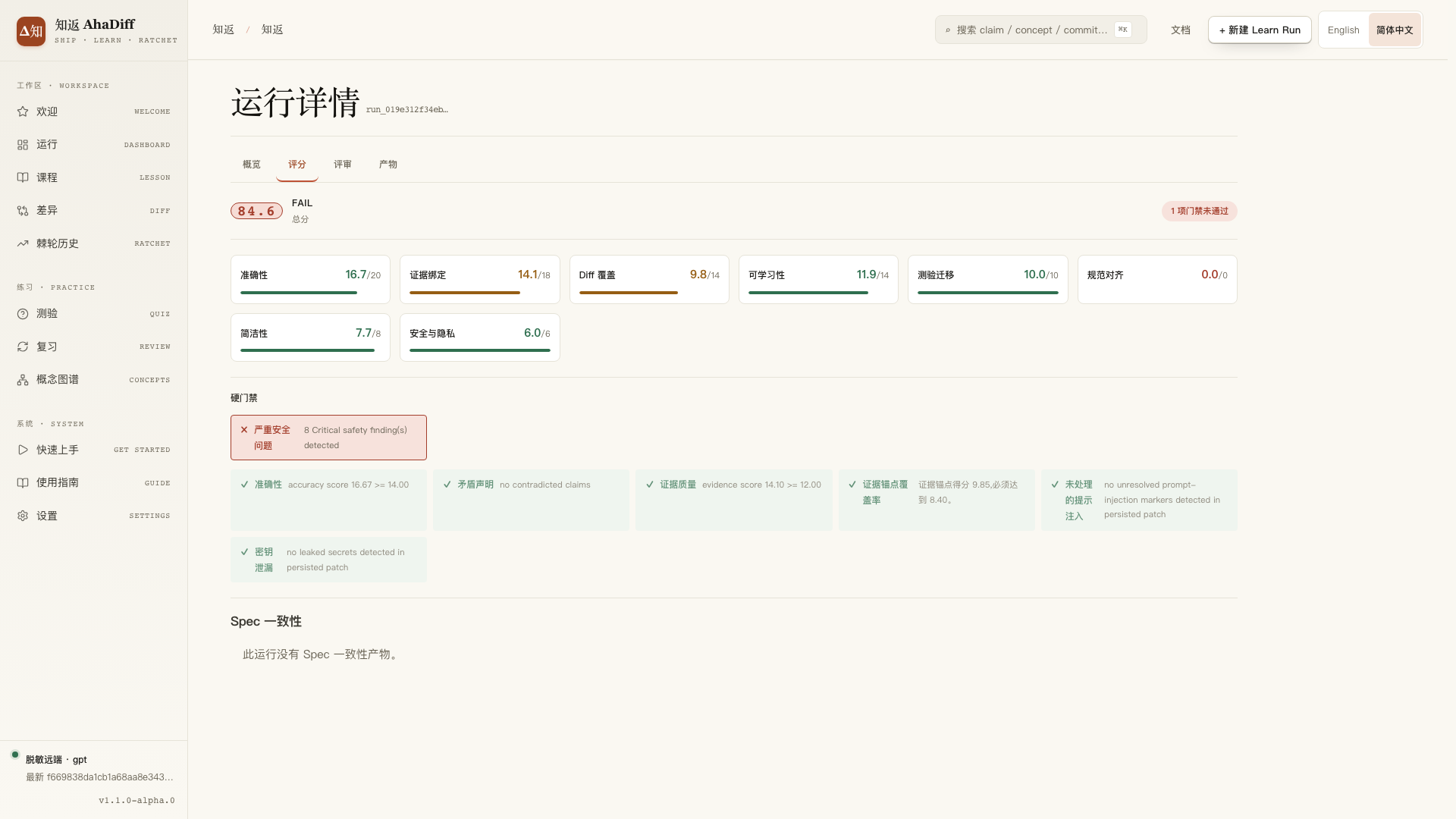
运行详情:八个维度的评分明细
觉得某次讲得还不够好?让它重学几遍,分数更高才留
打完分,你可能会觉得某次讲得还不够透,想让它再讲好一点。improve-run 能够解决这个问题。
对着某次 run 跑 ahadiff improve-run <run_id>,它会在你自己的项目里,拿这次改动把课程用更高质量重新生成几遍(默认 3 遍,专门盯着上次得分最低的那一维改进),再进行一次重新打分。只有新生成的分数确实比原来高,才会留下来。
Tips:整个改进过程它不碰 git、不改 prompt、也不覆盖你原来那条已经保存的记录。只是生成更好的学习课程。
怎么用:
可以直接从 pip 安装:
pip install ahadiff
装好并配好 provider 之后,核心就两步:
# 学一次最近的改动
ahadiff learn HEAD~1..HEAD
# 打开本地网页,看笔记、做测验、复习
ahadiff serve
serve 会提供webui,供你学习。想学暂存区里还没提交的改动,就 ahadiff learn --staged。改动从哪来都行:最近的提交、暂存区、补丁文件、两个目录的对比,一共支持十种来源,不仅仅是从 git diff中进行学习。
几个加强点:
-
你的代码diff默认不外传。隐私默认是
strict_local,diff 和代码都待在你本机;想用远端模型,得你自己显式打开,建议调成脱敏远端模式,日常使用更加方便。 -
用你自己的 key(BYOK),支持八种 AI 服务格式。如果不想使用api,避免隐私泄露的情况,也支持接入本地的 LM Studio 或 Ollama。
-
能导出成 Anki 卡片,复习完成后还能导出为anki卡片,接入自己日常使用的anki软件。
-
能给 AI 助手写本地规则和 skills。如果你希望 Claude、Codex、Cursor、Copilot、Gemini 这些工具也知道怎么使用知返,可以在项目里运行
ahadiff install --detect,再按需要执行ahadiff install codex或ahadiff install claude。它写的是项目本地指引,不会把代码上传出去。 -
改动太大也不怕撑爆模型。默认会按你选的模型上下文,自动算出这次最多捕获多少 diff(综合模型上下文、输出预留和中文 diff 的密度),不会一股脑全塞进去;想自己定也行,在 settings 里切成手动模式。
-
懒得每次手动跑。
ahadiff watch能盯着你的仓库,文件一改就自动触发 learn,适合边 vibe coding 边顺手把这次改动学掉。
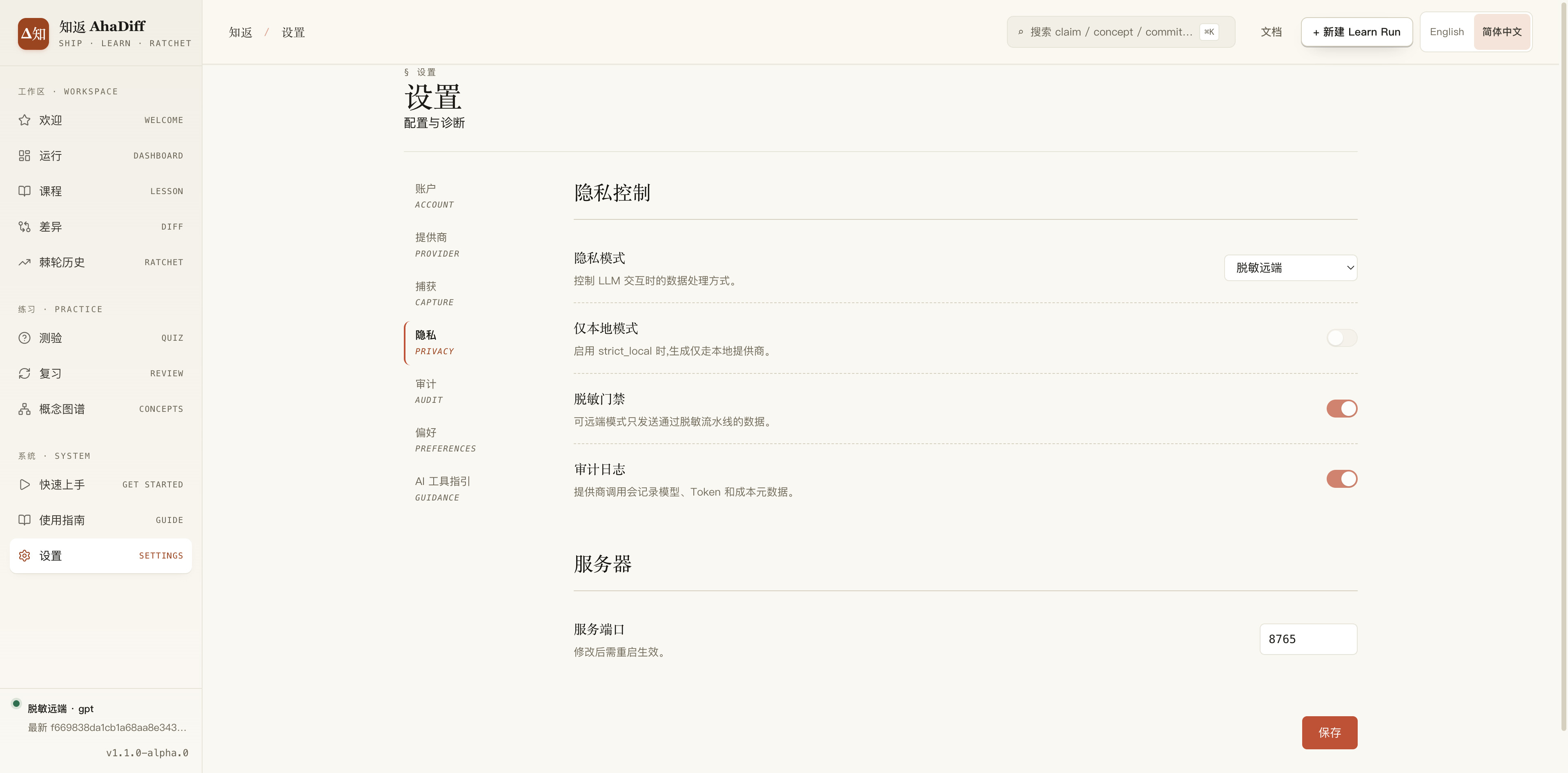
设置页:填 key、选模型、调隐私和捕获上限,都在这
部分限制
-
现在已经发布到 PyPI,直接
pip install ahadiff即可。源码安装也可以通过以下方式安装:uv tool install --editable .。 -
默认功能不需要额外安装;只有 FSRS 参数自动优化这种重依赖能力需要单独装
pip install 'ahadiff[optimizer]'。 -
Windows 上核心的 learn 和 serve 均可使用;但是需要注意的是,个别功能(比如
--compare-dir目录对比)目前只在 macOS / Linux上支持。
链接
-
项目介绍主页:知返 AhaDiff: AI 写完,Diff 教回
演示视频(使用remotion 制作,可能不够完善,请谅解):
光会用ai进行vibe coding 还不够,还得让它教会你点东西(知返开源项目介绍)_哔哩哔哩_bilibili
光让 AI 帮你 vibe coding,一路点确认就过,时间一长你会发现:项目做了不少,自己的代码功力没怎么涨。代码跑起来了,那点知识却没怎么留在你脑子里。知返 AhaDiff 就是让你从 AI 写的这些改动中让你学到真东西,从而内化成你的知识,它是个本地优先的开源工具,能从十种来源读你的一次代码改动,最近的提交、暂存区、补丁文件、两个目录的对比都算。读进来之后,它把这次改动变成能查证的学习材料, 视频播放量 80、弹幕量 0、点赞数 9、投硬币枚数 0、收藏人数 3、转发人数 2, 视频作者...
如果你也常有「这代码是 AI 写的,我想从中学到真东西」这种想法,欢迎尝试![]() 。
。
让你从每次vibe coding中学到真东西,而不只是无脑确认/继续。
觉得有用的欢迎给这个项目点个
有问题的或者觉得可以改进的地方的欢迎提pr和issues。
5 个帖子 - 3 位参与者