不同 API 服务的对我来说,非常实用。毕竟想省tokens,我还在用很多免费的模型,就是怕不稳定.
只讲实际能用、配置里能落地的部分,避免把不存在的配置项写进去。
如果有错误欢迎佬友指正 ![]()
我的Hermes 的模型配置思路
Hermes 的配置核心在 ~/.hermes/config.yaml。
模型相关配置主要分几层:
主对话模型:负责正常聊天、代码、工具调用、任务执行。
辅助模型:负责压缩上下文、图片理解、网页提取等后台任务。
Fallback Providers:主模型失败时切到备用供应商。
Custom Providers:接入 OpenAI 兼容接口,比如 vLLM、Ollama、LM Studio、SGLang 或第三方中转 API。
Credential / Auth:API Key 或 OAuth 凭据。
最常见的配置结构大致是:
model:
default: gpt-5.5
provider: custom
base_url: https://example.com/v1
api_key: sk-xxx
context_length: 128000
其中:
model.default:模型名称
model.provider:供应商名称
model.base_url:自定义 OpenAI 兼容端点时使用
model.api_key:API Key
model.context_length:上下文长度
Hermes 要求模型上下文窗口不能太小。实际使用 Agent、工具调用、长会话压缩时,建议至少 64K tokens 起步。本地模型也建议把上下文开到 65536 或以上。
Hermes 支持哪些供应商我就不说了佬友自己就可以看到
切换模型的几种方式
方式一:交互式选择
hermes model
这是最推荐的方式。它会引导你选择 provider、填写凭据、选择模型。
方式二:查看和修改配置
查看配置:
hermes config
打开配置文件:
hermes config edit
也可以直接设置某个配置项,例如:
hermes config set model.provider openrouter
hermes config set model.default anthropic/claude-sonnet-4
如果是自定义接口:
hermes config set model.provider custom
hermes config set model.default your-model-name
hermes config set model.base_url https://example.com/v1
API Key 建议放在 .env 或配置里由 Hermes 管理,不要写进公开文章、截图或 Git 仓库。
方式三:会话内临时切换
在 Hermes 会话里可以用:
/model openrouter/anthropic/claude-sonnet-4
这种方式适合临时测试。长期默认模型还是建议写入 config.yaml。
主模型和辅助模型
Hermes 不是所有任务都必须用同一个模型。
主模型负责核心对话和 Agent 执行;辅助模型可以负责压缩、视觉、网页提取等后台任务。这样可以避免“用旗舰模型做摘要”这种浪费。
常见配置示例:
model:
default: claude-sonnet-4
provider: anthropic
auxiliary:
compression:
provider: openrouter
model: openai/gpt-5-mini
vision:
provider: openrouter
model: openai/gpt-4o
建议:
主模型:选择工具调用稳定、上下文长、代码能力强的模型。
压缩模型:选择便宜但摘要能力不错的模型。
视觉模型:选择明确支持图片输入的模型。
如果辅助模型没有配置好,某些任务可能会回退到自动检测逻辑,或者使用主模型兜底。为了稳定,建议主动配置。
Fallback Providers:主模型备用链
当主模型遇到限流、服务错误或连接失败时,Hermes 可以尝试备用模型。
正确的配置项是 fallback_providers,不是 fallback_models。
示例:
model:
default: gpt-5.5
provider: custom
base_url: https://primary.example.com/v1
api_key: sk-primary
fallback_providers:
- provider: custom
base_url: https://backup.example.com/v1
api_key: sk-backup
model: claude-sonnet-4
- provider: openrouter
model: anthropic/claude-sonnet-4
触发条件一般包括:
HTTP 429:限流
HTTP 503:服务错误
HTTP 529:过载
连接失败
需要注意:
Fallback 是按顺序尝试的,不存在 fallback_strategy: random、cheapest_first 这类配置。
也不存在 fallback_on 这种配置项;触发条件是内置的。
主模型 fallback 一旦在当前会话触发,通常会在该会话里继续使用 fallback 后的模型。
旧版可能支持单个 fallback_model,但新写法建议使用列表形式的 fallback_providers。
辅助任务也可以单独配置 fallback
辅助任务不继承主模型的 fallback_providers,它们有自己的 fallback 链。
示例:
auxiliary:
compression:
provider: custom
base_url: https://primary.example.com/v1
api_key: sk-primary
model: gpt-5-mini
fallback_chain:
- provider: custom
base_url: https://backup.example.com/v1
api_key: sk-backup
model: deepseek-chat
- provider: openrouter
model: openai/gpt-5-mini
vision:
provider: openrouter
model: openai/gpt-4o
fallback_chain:
- provider: anthropic
model: claude-sonnet-4
辅助任务 fallback 的触发更偏向容量或额度问题,例如:
HTTP 402:余额或额度耗尽
明确的日/月额度耗尽
连接失败
- 注意:普通临时 429 不一定会触发辅助 fallback,因为 Hermes 会尊重你显式指定的 provider。
自定义 OpenAI 兼容端点
我相信很多佬友跟我一样会用本地模型或第三方中转服务,这时最常见的就是 custom provider。
例如 Ollama:
model:
provider: custom
default: qwen3-coder:latest
base_url: http://127.0.0.1:11434/v1
api_key: ollama
context_length: 65536
例如 vLLM:
model:
provider: custom
default: Qwen/Qwen3-Coder
base_url: http://127.0.0.1:8000/v1
api_key: dummy
context_length: 131072
vLLM 启动时可以类似这样:
vllm serve Qwen/Qwen3-Coder --max-model-len 131072
Ollama 需要确认模型上下文已开够。不同版本设置方式不完全一样,不建议只写死一个命令,重点是确认 context 至少 64K。
多个自定义供应商
如果有多个自定义端点,建议用 custom_providers 起不同名字。(我就是这么干的,感觉特别方便,需要多少自己加)
示例:
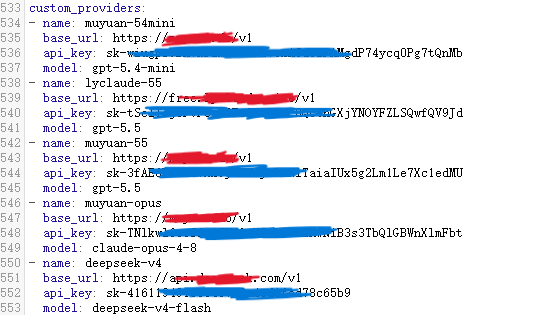
然后在主模型或 fallback 里引用:
model:
default: gpt-5.5
provider: custom
base_url: https://api.example.com/v1
api_key: sk-tSeI...YFZLSQwfQV9Jd
fallback_providers:
- provider: custom
base_url: https://api.example2.com/v1
api_key: sk-wiu...4ycq0Pg7tQnMb
model: gpt-5.4-mini
注意:custom_providers 的 name 必须唯一。重复名字可能导致后面的配置覆盖前面的配置。
小结
Hermes 的模型配置体系,重点不是“支持多少模型”,而是它把模型、供应商、辅助任务、fallback、自定义端点拆开了。
这样做的好处是:
- 主模型可以选最强的;
- 辅助任务可以选便宜的;
- 一个供应商挂了可以切备用;
- 本地模型和第三方 OpenAI 兼容服务都能接;
- 不同平台、不同任务可以逐步做精细化配置。
对小白用户来说,最推荐的入门路线是:
- 先用
hermes model跑通一个主模型; - 再配置
fallback_providers; - 然后配置
auxiliary; - 最后再折腾本地 vLLM / Ollama / LM Studio。
- 这样最稳,也最不容易把配置写乱。
我以前就是这么做的,后来慢慢的学,特别在Linux 学到很多以前看不到的技术
最后如有错误的地方,欢迎佬友们指正
1 个帖子 - 1 位参与者