今日,SILX AI 宣布推出其 Quasar 基础模型系列的首个公开版本——Quasar-Preview。
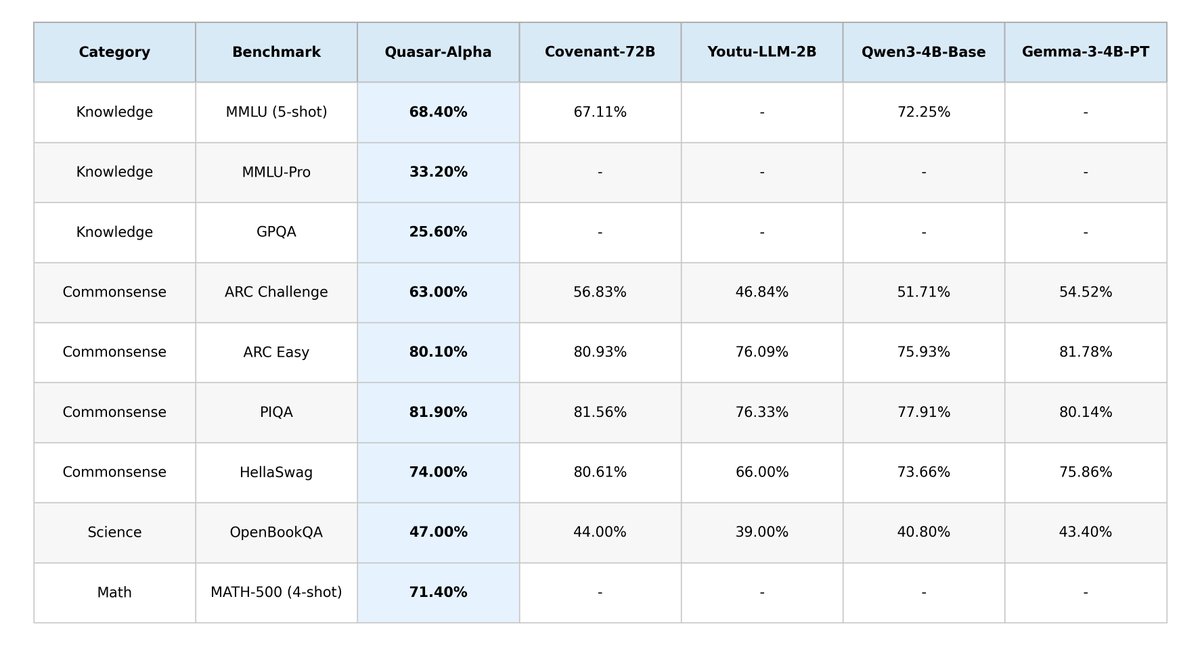
Quasar-Preview 并非旨在与当前顶尖模型“刷榜”竞争,而是一个用于验证和探索前沿架构的奠基之作。它的主要技术规格包括:采用约 18B 总参数的混合专家(MoE)架构,其中激活参数(Active Parameters)仅为 2B 级别,保持了极高的推理效率。配置了实验性的 500万(5M)Token 上下文窗口,采用 Safe NoPE / DrOPE 风格的阶段性长上下文扩展方法,专为未来的基于内存的系统而设计。模型基于 Loop Transformer 和 Quasar 混合注意力构建,内部包含了 Quasar、Raven 和 GLA 混合层,并结合了稀疏 MoE 路由技术。
目前训练所用的 Token 数量在 1T 到 1.5T 之间(其中长上下文扩展路径目前接收了不到 1B 的 Token)。
官方强调,Quasar-Preview 并非最终形态的 Quasar 模型,也不能代表该架构的最终质量。它采用 MIT 协议开源发布,旨在将架构公之于众,方便研究人员进行测试与开发。
该模型依托 Bittensor(SN24)去中心化基础设施进行训练。SILX AI 计划在未来通过以下方式持续提升模型性能:
- 迭代式的子网训练与知识蒸馏
- 更长的训练周期与更强的后训练
- 进一步的长上下文扩展训练以及架构更新

silx-ai/Quasar-Preview · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
1 个帖子 - 1 位参与者
来源: LinuxDo 最新话题查看原文