- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
(全文上万字符长时间手打+十数张图,先前已经多次回复说明情况却都被认为是ai生成举报,上百楼内容丢失,哪怕为了其他佬友的认真讨论与交流的内容都请勿随意举报!如有意见请友好私信交涉)
注:这里有一个三分钟使用极简教程,正式使用前推荐看看:【全开源免费!抢先体验属于个人的Easy Research!Obsidian开发者手把手教你三分钟速通NotEMD!-哔哩哔哩】 https://b23.tv/lqR0RlA
2026.05.25:
在版主提醒下,L站禁止给群组引流,有需要进一步交流需要请给项目点star或私信本人。
安装
- Obsidian 社区插件里直接搜索
Notemd - 或者去 GitHub 仓库查看源码和 release
项目地址:
- GitHub: notemd github项目
- Obsidian Community Plugin: 搜索
Notemd
下面是正文
这两年关于 AI 读论文的讨论很多。但这个阅读的痛点始终存在:读完以后,内容有没有留下来?
在对话框里提问很方便,模型也能很快给出总结、翻译和解释。但过几天再回看,常见结果只有一个模糊印象。论文的核心概念、方法关系、实验设置、局限性,以及它和已有知识的连接,往往没有真正进入自己的知识库。
所以我现在更在意一件事:把论文阅读过程中有价值的内容,持续写回 Obsidian。
Notemd 就是在这个场景里我用得比较顺手的工具。它把论文笔记、概念卡片、研究摘要、翻译、图表和工作流放在同一个工作台里,让一次阅读不只停留在一次对话,而是变成后面还能继续调用的资料。
一句话介绍:
Notemd 是一个开源的 Obsidian 社区插件,用来把论文阅读过程中的概念链接、概念笔记、原文证据摘录、背景补充、翻译、图表和工作流沉淀回知识库,并支持多语言 UI、README 和内容转换。
实际阅读状态示例:
多语言支持:
我想解决的问题:读完一篇之后,还能继续积累
我现在看“AI 读论文”,关注点已经在长期积累能不能形成。
你当然可以把 PDF 丢给模型,让它做总结、翻译、解释公式、分析贡献。这些都很有用。但论文不是孤立存在的。每次读到的新术语、方法、数据集、实验范式,理论上都应该慢慢长进自己的知识网络里。
我更想要的结果是这些:
- 一篇论文读完以后,关键概念被自动补成
[[wiki-link]] - 新出现的概念可以继续生成概念笔记
- 我关心的问题能直接定位到原文证据,而不只是拿到一段转述
- 背景资料和补充搜索能附着在当前笔记旁边
- 复杂方法链路可以压成 Mermaid 或图表,方便回看
- 这些结果都留在 vault 里,而不是散在不同聊天记录中
Notemd 的价值也正是:它把论文阅读变成一条可以复用、可以回看、可以持续补充的知识流。
和聊天式 AI 相比,Notemd 更适合把结果沉淀进知识库。
维度
聊天式 AI(如Smart Composer插件的功能)
Notemd
核心落点
当前会话
当前笔记和 vault 文件
结果形态
一段回答
链接、概念笔记、译文、图表、日志、工作流产物
适合场景
快速问答、临时解释
长期阅读、积累、复用
主要风险
聊完就忘,不利于回忆与搜寻
需要自己维护知识库结构
这两种方式并不冲突。我自己也会继续用对话式 AI (例如Obsidian中的Smart Composer等插件)针对论文做即时追问。但如果目标是让今天读过的东西,三周后还能准确记忆与获取,那么文件化、结构化和可回写会更重要。
结构化总结:
我现在比较顺手的一套论文工作流
Notemd 当前处理的是 Markdown / txt 内容,不是直接载入 PDF(但打开开发者选项后个别不需要修改原文的任务是支持载入其他格式)。这会让整个流程更干净,并且MD是AI的原生语言。
1. 先把 PDF 变成 Markdown
我一般会先用 MinerU 之类的工具做 PDF → Markdown,再把结果放进 Obsidian。 (当前MinerU在目前的免费软件里使用起来解析质量高且速度较快)
这样做有几个直接好处:
- 原文结构更清晰
注: v1.9.1已支持章节结构提取功能

-
后续链接、翻译、提取、图表都围绕同一份 Markdown 笔记发生
-
你的“论文阅读结果”本身就是知识库资产
注意,后面的大部分自动化,都要求原文已经进入你的知识库,是Notemd可处理的文件。
2. 先做概念链接,再做概念沉淀
导入 Markdown 以后,我一般先运行这两个指令:
处理文件(添加链接)| Process file (add links)从标题批量生成| Batch Generate from Title
前者会把论文里的关键概念补成 [[wiki-links]],后者则可以借助高质量AI(比如降智前的Gemini-3.1-pro)把每个概念扩充为深入的领域知识与术语间关系的总结,支持调用搜索 api(比如 Tavily)做定向搜索后生成。
很多论文难读,原因很简单:默认你已经知道太多术语。backbone、训练范式、benchmark或是统计指标,而实际上需要你临时去查,特别是当你不了解这个领域时更是无从查起。
因此我通过Notemd将这些概念用ai提取后直接沉淀到固定的或者是自定义领域的概念文件夹里。这样第二篇、第三篇相关论文读下去时,已有概念会越来越完整,不需要每次从头补背景。
如果你愿意的话可以打开概念日志,每次新增了哪些概念都有记录。并且,我已经将这套流程固化为一键处理按钮,不需要拆解单独执行(但需要注意tokens消耗),最大化便利佬友们使用。

3. 用“提取特定原始内容”做证据导向的精读
“提取特定原始内容”顾名思义,是获取原文中的依据,适合继续做精读笔记、组会汇报,或者后面写 related work 时快速回查。
你可以先在设置里定义一组问题,例如:
- 这篇论文的核心贡献是什么?
- 作者如何定义问题?
- 实验设置是什么?
- 主要 baseline 有哪些?
- 作者明确承认了哪些 limitation?
然后让插件从当前论文里逐字提取对应原文片段。
如果你希望明确知道“这句输出到底对应原文哪一句”,记得使用这个功能
4. 不懂的背景用 Research & summarize试试
如果需要临时查阅当前论文或笔记的特定只是,我不会立刻跳出 Obsidian 去开很多网页,可以在当前笔记旁边做 Research & summarize。它会调用你配置好的搜索服务和 LLM,把主题相关的补充信息整理出来,附加回当前笔记。
- 背景知识不散在浏览器标签页里
- 你查过什么,和当前 paper 绑定在一起
- 后面回看时,论文旁边就是当时补的上下文
我主要用它补背景和补术语网络,不替代正式文献检索。在课题早期扫盲阶段能明显降低阅读门槛。
5. 英文精读压力大时,直接翻译,但翻译结果也应该保存到本地
当前很多 AI 翻译论文的方案,问题通常是单次翻译没有有效落盘,Translate current file 这个链路的价值,在于它会把译文作为 Obsidian 里的另一份产物保存下来,成功后还会直接在侧边栏打开。
多语言知识库用户可以实现:原文、译文、概念卡片、研究摘要都能在同一个 vault 里互相引用,不需要来回搬运。并且由于UI Locale 和 Task Output Language 是分开的,界面语言可以跟着 Obsidian 走中文,任务输出也可以保持英文,反过来配置也可以。科研场景里,这种拆分很方便。
这是效果图,内容摘选自 Feynman 的物理学讲义:
6. 最后把理解压缩成图
论文阅读与领域学习的过程中很常见的问题是:脑子里一堆概念,但没整理出结构。
有这两个功能可以辅助解决:
Summarise as Mermaid diagramGenerate diagram (experimental)
前者更适合方法流程、模块关系、因果链路这类结构化内容。后者在当前版本里已经覆盖 Mermaid、JSON Canvas 和 Vega-Lite 等图表路径,其中 dataChart 还能用 Vega-Lite 生成更规整的数据图。
图是一种"理解压缩层"。让 AI 把论文画成流程图、关系图或数据图,它必须先把结构显式整理出来。检查图的时候,也更容易一眼看出哪里有问题。
注意:图不是事实本身。AI 生成的图,尤其是科研图,只适合当草图、摘要层和检查层,不适合不经核对直接当最终结论。
如图,v1.8.4最新版支持众多种类图的生成:
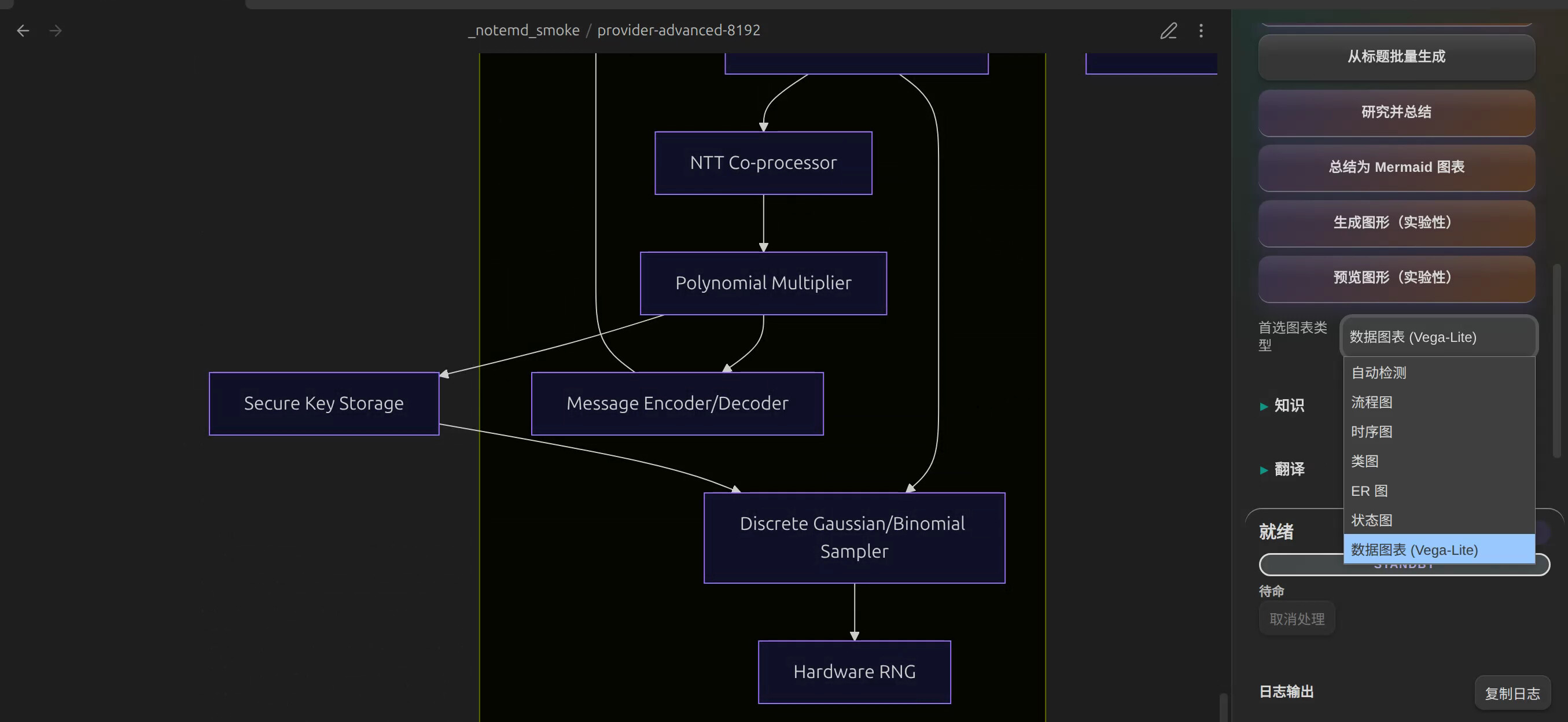
下面再给一些图类型的举例:
Mermaid正常图:

时序图:
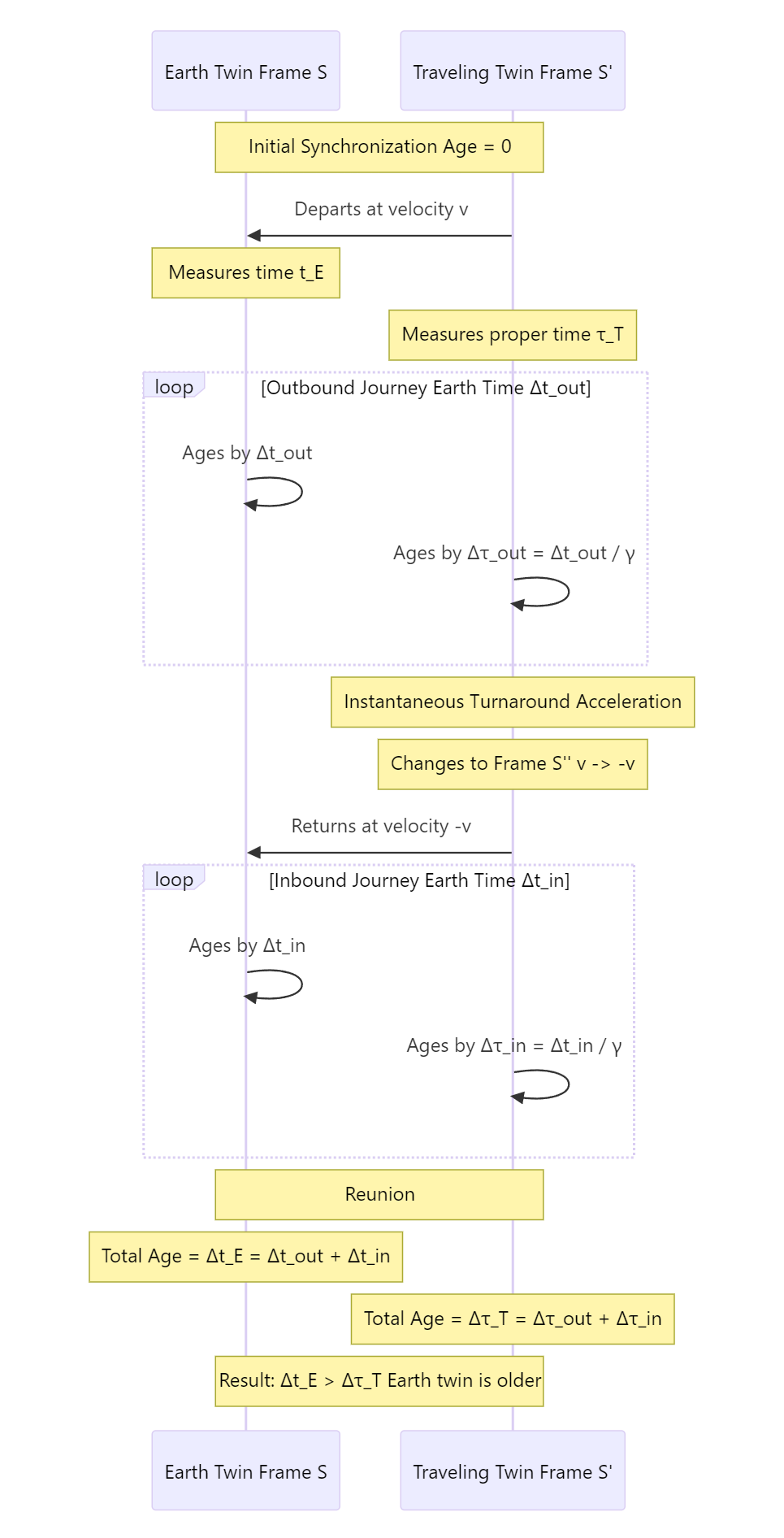
7. 最后用工作流把这些动作串起来
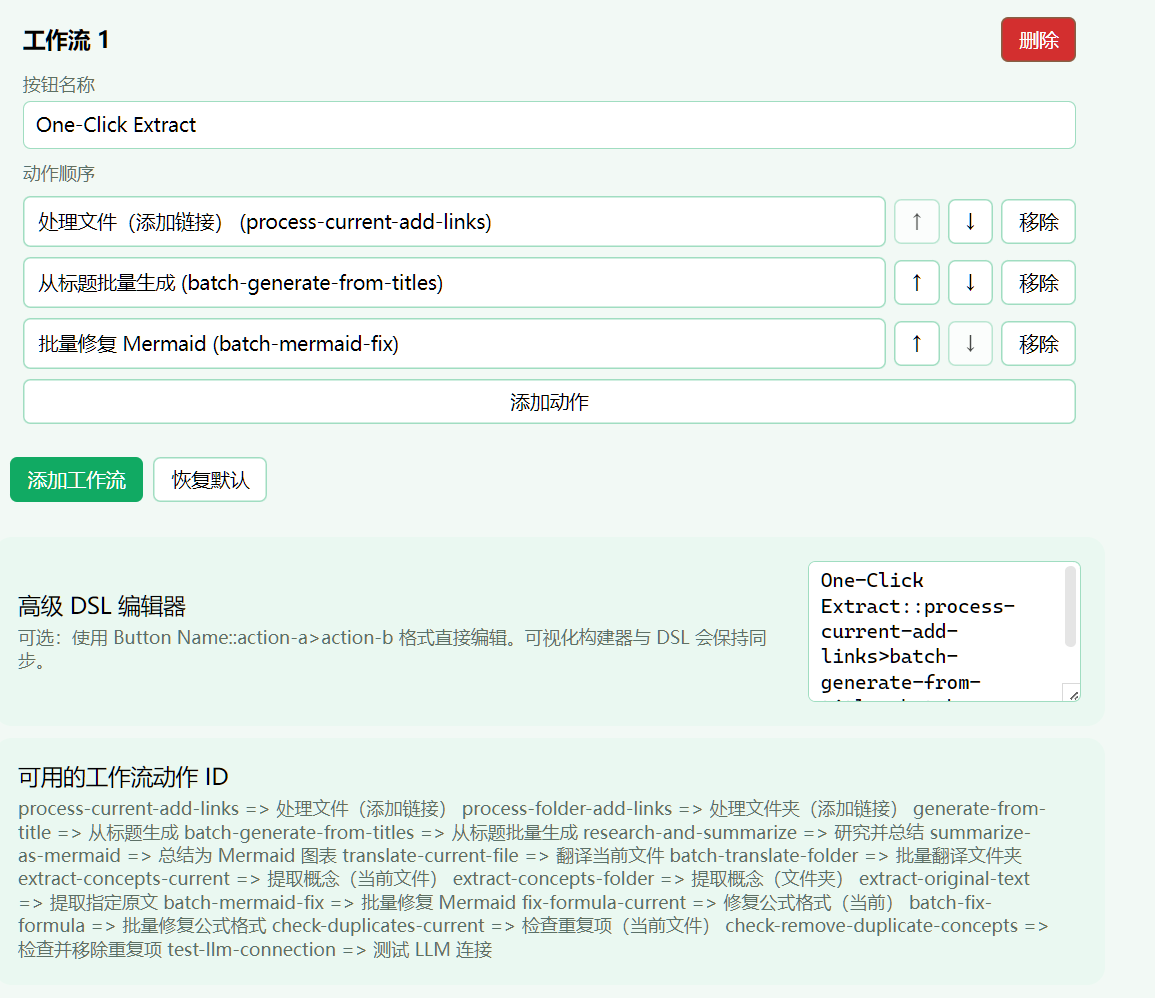
如果上面这些动作每次都手动点一遍,久了还是会烦。所以 Notemd 里我很喜欢的另一个点是:你可以把常用动作编成自己的 One-Click Workflow。
默认就有一个 One-Click Extract功能把几个动作串起来跑。除此之外,你也可以按自己的论文习惯重组,比如:
论文入库::process-current-add-links>extract-concepts-current>research-and-summarize>summarize-as-mermaid
在设置中有非常高度自定义工作流的支持:
对我来说,工作流的意义除了少点几次按钮,还有真正把阅读习惯固定下来。你跑得越多,知识库结构就越稳定,后面的复用价值也会越高。
这个项目更偏实际工作流程落地,有下面这些突出优点
-
完整开源。github开源,具体设置有文字+多图说明。
-
模型选择自由。支持 OpenAI、Anthropic、Google、DeepSeek、Qwen、Ollama,以及通用
OpenAI Compatible网关。
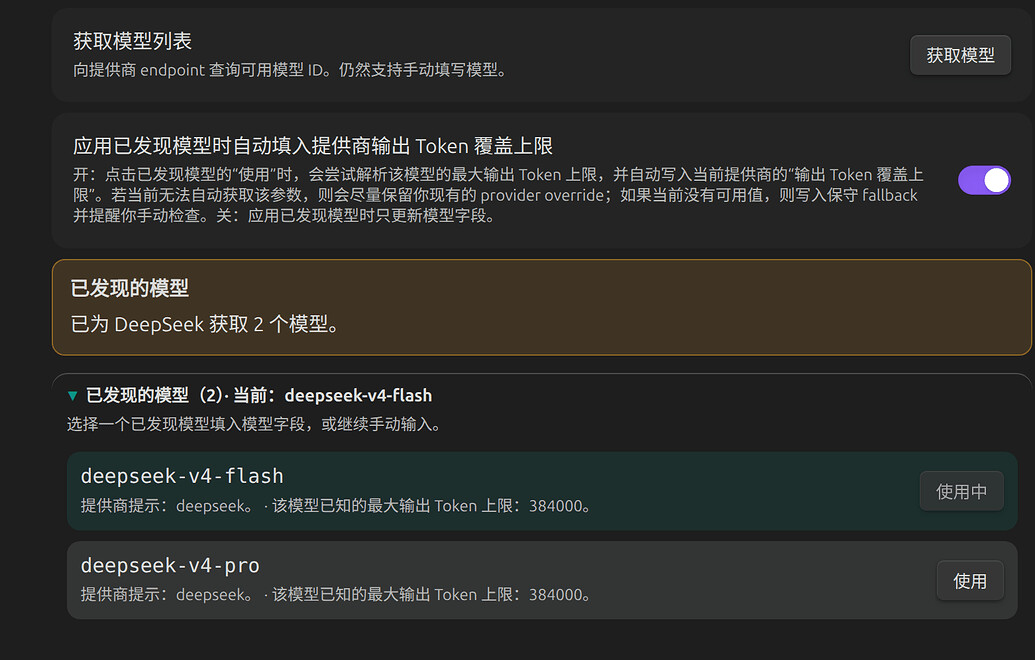
注:v1.9.1已支持“获取模型列表”功能。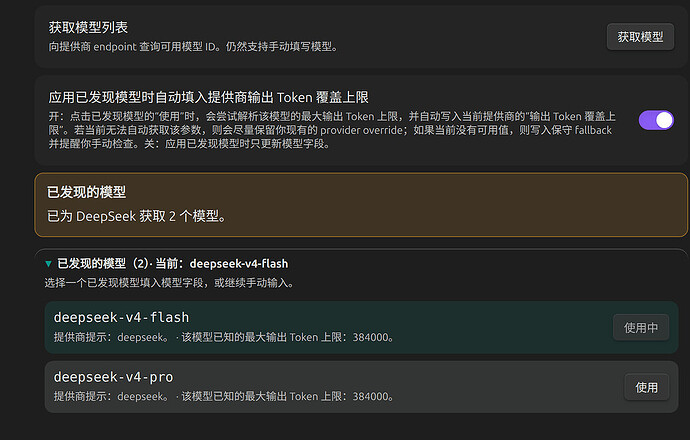
-
不同的任务均支持对特定的模型进行配置。对于链接、研究、翻译以及生成等任务,均能够独立地去进行 provider 以及 model 的选用。
-
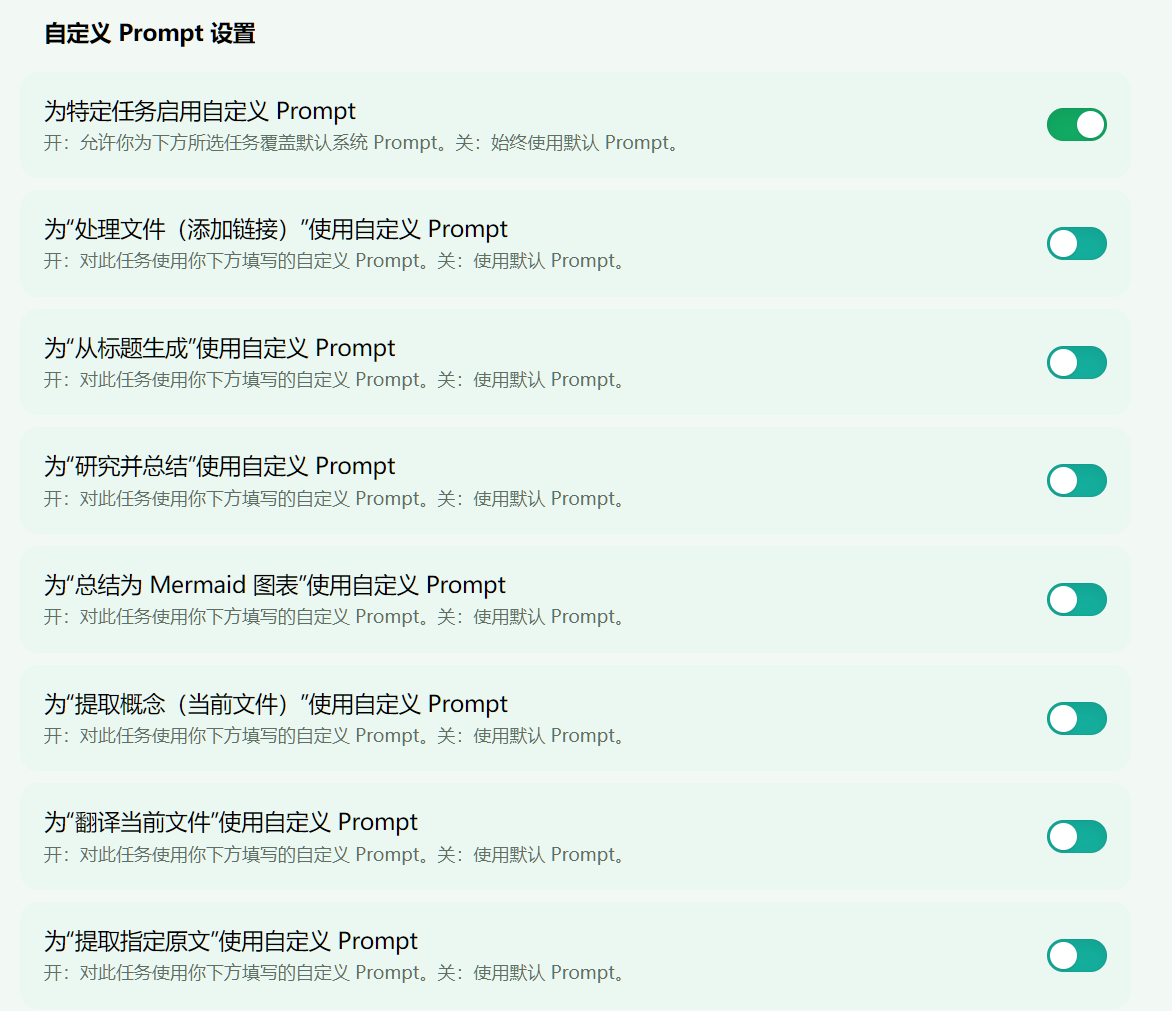
对于每一个具体需要去执行的任务,都支持开展 prompt 的修改工作。这就为插件在功能拓展方面提供了相当充裕的空间。
- 结果都会以文件的形式来予以保存。在开展学习的过程当中,插件会把相对应的链接、概念笔记、译文、图表以及日志都进行留存。
- 在本地用户友好性方面表现得十分出色。针对那些已经习惯于去使用 Obsidian 的用户来说,这一工具可以直接在既有的工作台环境当中去嵌入 AI 相关的能力,这样一来,就完全不需要再去对一整套既有的笔记体系开展任何的替换工作。
它能帮你构建"外部大脑",但真正记住与掌握,开始实践的只能是你自己。
哪些人应该尝试这个插件:
- 已经在用 Obsidian 管理读书或论文笔记的人
- 面对较大规模的文献阅读量,且期望将零散理解逐步构建为系统化知识网络的人
- 不满足于“总结一下”,而是想把概念、证据、图表和上下文都留下来的人
- 期望将翻译、搜索、概念提取以及图表生成整合至同一工作台之中的人群
- 对模型选择上期望自由切换云端和本地部署模型的人
如果你只是偶尔看一两篇 paper,能协助你完成翻译与核心概念的提取工作,上手门槛很低,并且有保姆式视频教学。
如果你有长期积累需求,它的价值会更为显著,因为这些结果最终均会沉淀于个人知识库之中。
如果大家感兴趣,后面我还可以再单独整理一篇更偏实操的帖子专门针对大家的后续问题,比如:
- 我怎么配置提取问题模板
- 如何把 prompt 开展有针对性的调整工作,来让它得以深度契合到不同的学科领域以及具体的任务场景当中
- ……
如果觉得喜欢有所收获,对你有帮助,就支持一下吧!
3 个帖子 - 3 位参与者