- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
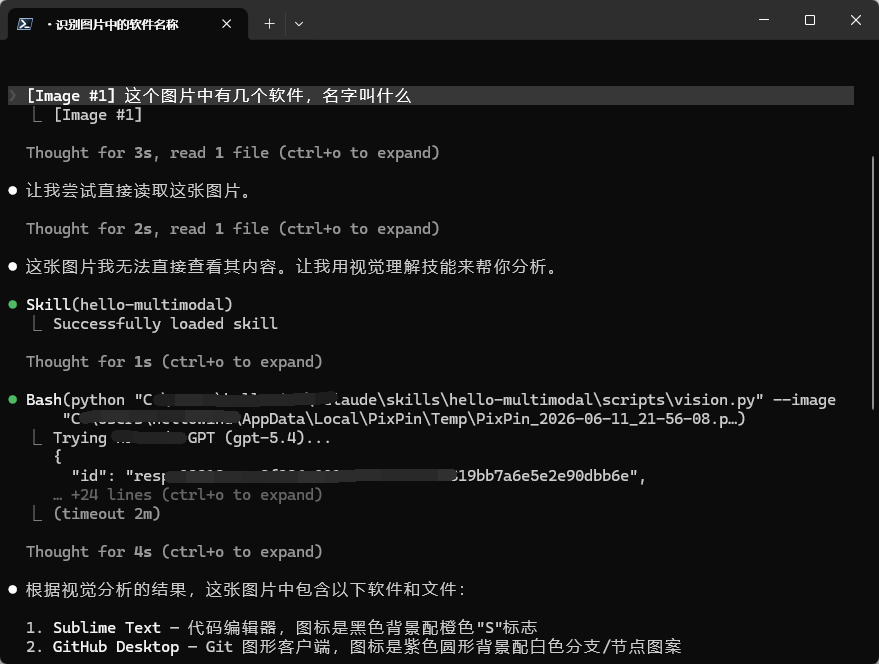
大家在用入Claude Code时,如果接入DeepSeek等文本大模型无法视觉理解,使用原生 Claude大模型也不支持图片生成。
闲来无事,做了个Hello-Multimodal SKILL解决了这个问题:给没有 vision 的模型补上视觉理解,给 Claude Code 补上生图能力。
它做了什么
两件事:给 DeepSeek 等文本大模型补上视觉理解能力,给 Claude Code 补上图片生成能力。主模型不支持时自动路由到 GPT 多模态模型处理。
适用场景
1. DeepSeek 视觉理解
你:"请分析这张截图的 UI 布局"
Claude Code 发现当前模型没有 vision → 自动调 Hello-Multimodal 技能 → GPT-5.4 看图 → 返回结果
全程你没有切换模型,也没有报错。
2. 代理映射陷阱
如果使用了本地路由把 DeepSeek 映射成 claude-opus模型,Claude Code 看到模型名以为有 vision,实际没有依然会无法识图。
Hello-Multimodal 技能不认模型名,只认实际能力。发请求 → 失败 → 自动降级。无论本地路由代理怎么映射都不影响。
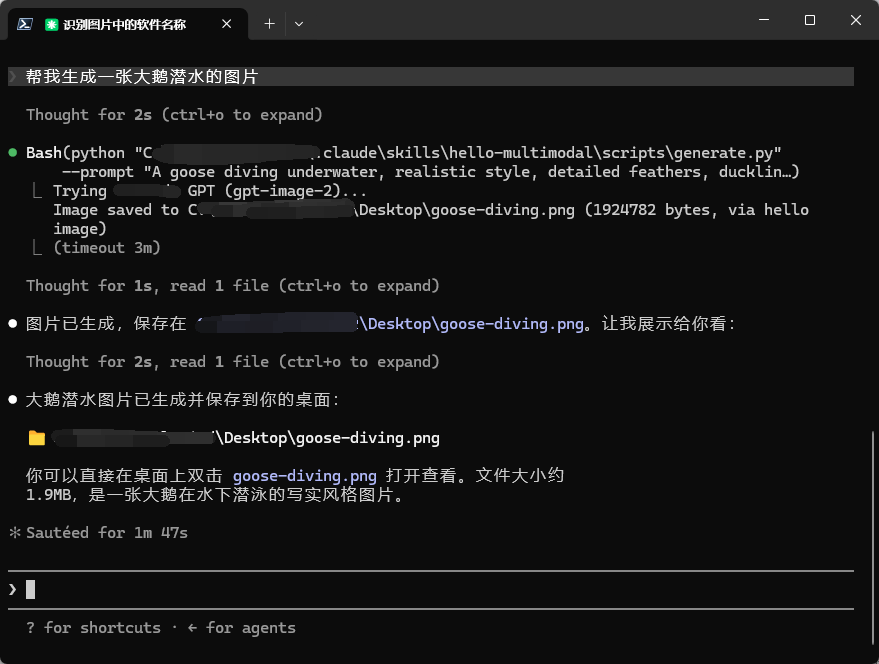
3. Claude Code 生图
Claude Code 不管用哪个模型,本身都不支持图片生成。Hello-Multimodal 补上了这个缺口——生图需求自动交给 gpt-image-2,引擎委托给 helloimage,继承其全部端点 fallback。
如何配置
把技能目录的config.example.json改名为config.json,然后把其中的api-key和base_url、model配置好。
{
"channels": [
{
"name": "GPT渠道",
"base_url": "https://xxx.com",
"api_key": "sk-xxx",
"model": "gpt-5.4",
"image_model": "gpt-image-2",
"image_api_key": "sk-img-yyy"
}
]
}
支持最多 3 个渠道按优先级 fallback。生图可以单独配置 api_key 和 base_url,适配独立计费分组。
安装方法
建议把仓库地址扔给AI,让AI帮你安装插件。
https://github.com/hellowind777/hello-multimodal
配置完成后正常使用 Claude Code,视觉和生图任务会自动路由。
如何使用
安装好本技能后,并配置好对应的gpt模型API信息,然后新开claude code窗口直接使用自然语言对话就可以识别图片和生成图片。
声明:本技能由AI生成且公开开源,不含有任何盗取API的代码和功能,如果使用后导致API被盗与本技能无关。请自行斟酌。
使用效果图如下:

1 个帖子 - 1 位参与者