今天终于把影视短剧创作平台的1.0版本(Docker本地包)完成并推送到Github上面去了,算是小小的一个里程碑,所以想记录一下,有点啰嗦。Vibe Coding的应用,大佬们别笑话! 去年下半年因为爱好接触到了动漫视频制作,也因为一时的冲动,怒冲了一年的可灵黑金会员,但当时做视频需要结合gemini规划分镜的图片及视频提示词,再到可灵的网页版上面输出视频,就觉得非常麻烦。当时我就想为什么不做…
2.0版本的升级终于快到尾声了,记录一下。
之前1.0版本主要是把各功能区全部搭建好了,发现对小白用户来说不是很友好,太多的功能页面不知道如何下手,所以就新增了一个模型—创作向导,也就是小白模式,跟着流程做就完事,首先把界面简洁化了。
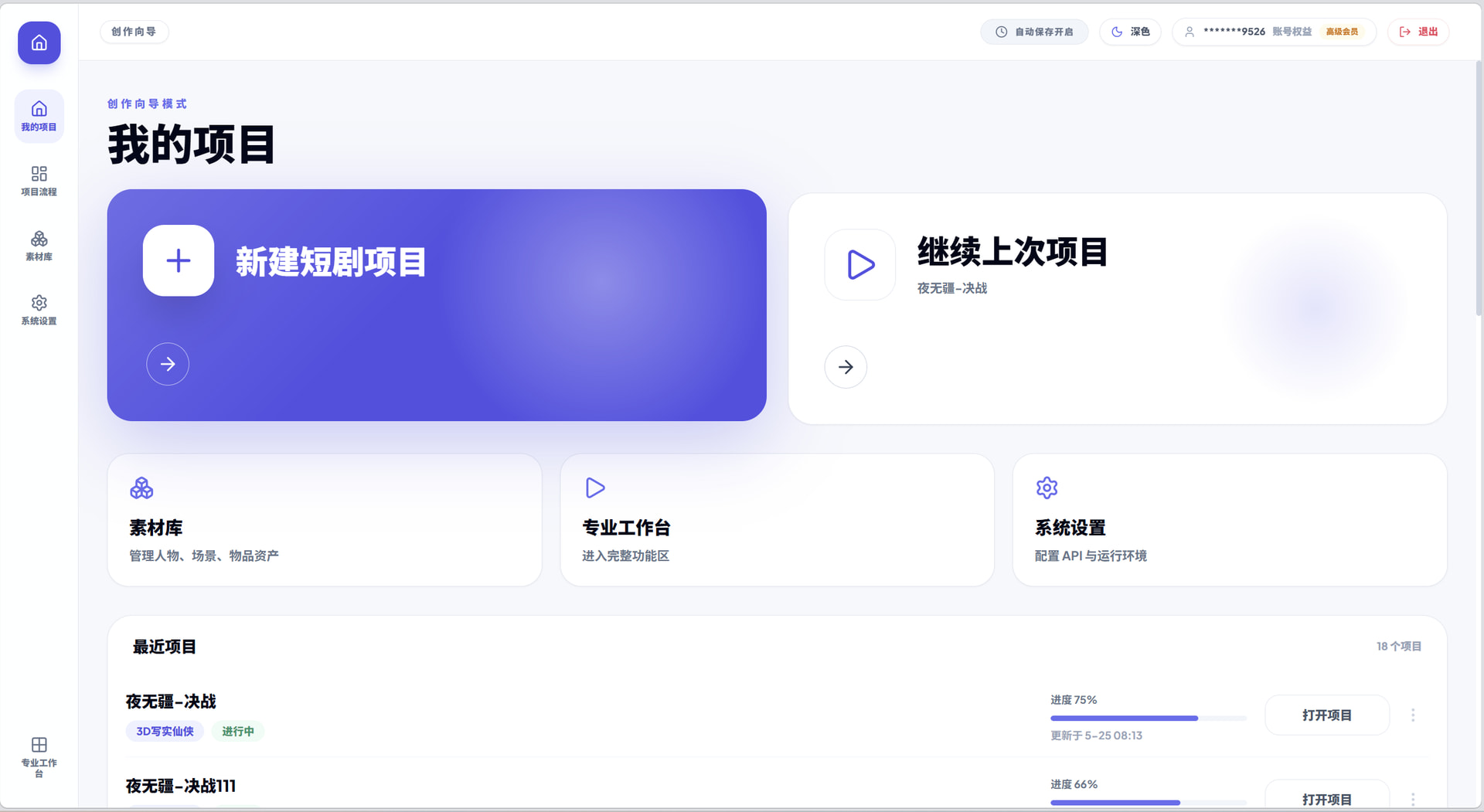
创建项目后,小白用户就能够清晰的了解整个创作的流程和逻辑,一目了然,在当前页只需要导入剧本内容,选择内容风格和画面比例,底层逻辑会自动解析后续的资产库所需的内容。
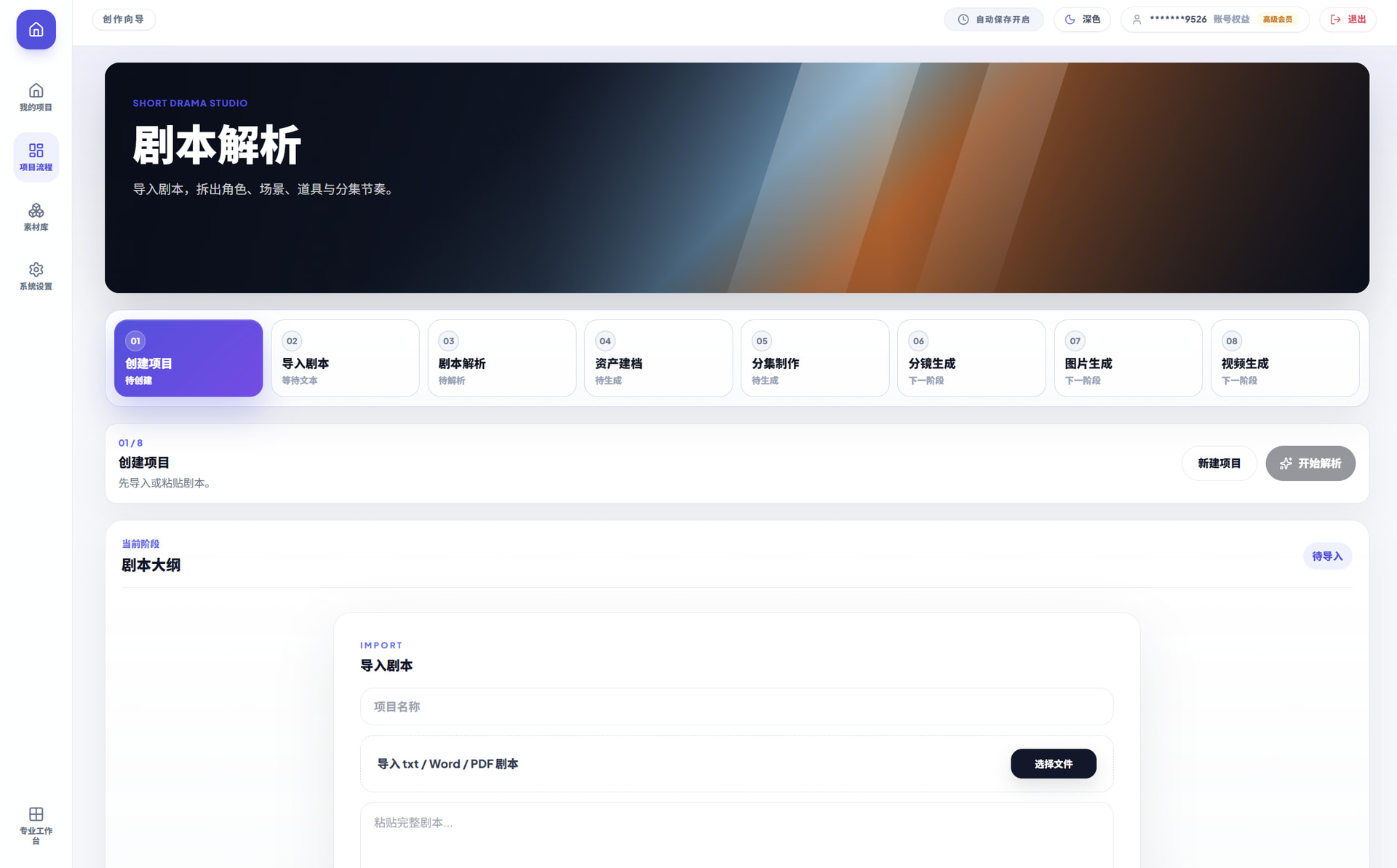
对于小白用户,如何写提示词是最头痛的一件事情了,但是在我的这个应用里面,最不怕的就是写提示词了,因为完全不需要你写,剧本解析会把所有的人物、场景、物品以及后续的生图、生视频提示词全部输出,你只需要点点点点点就行啦!
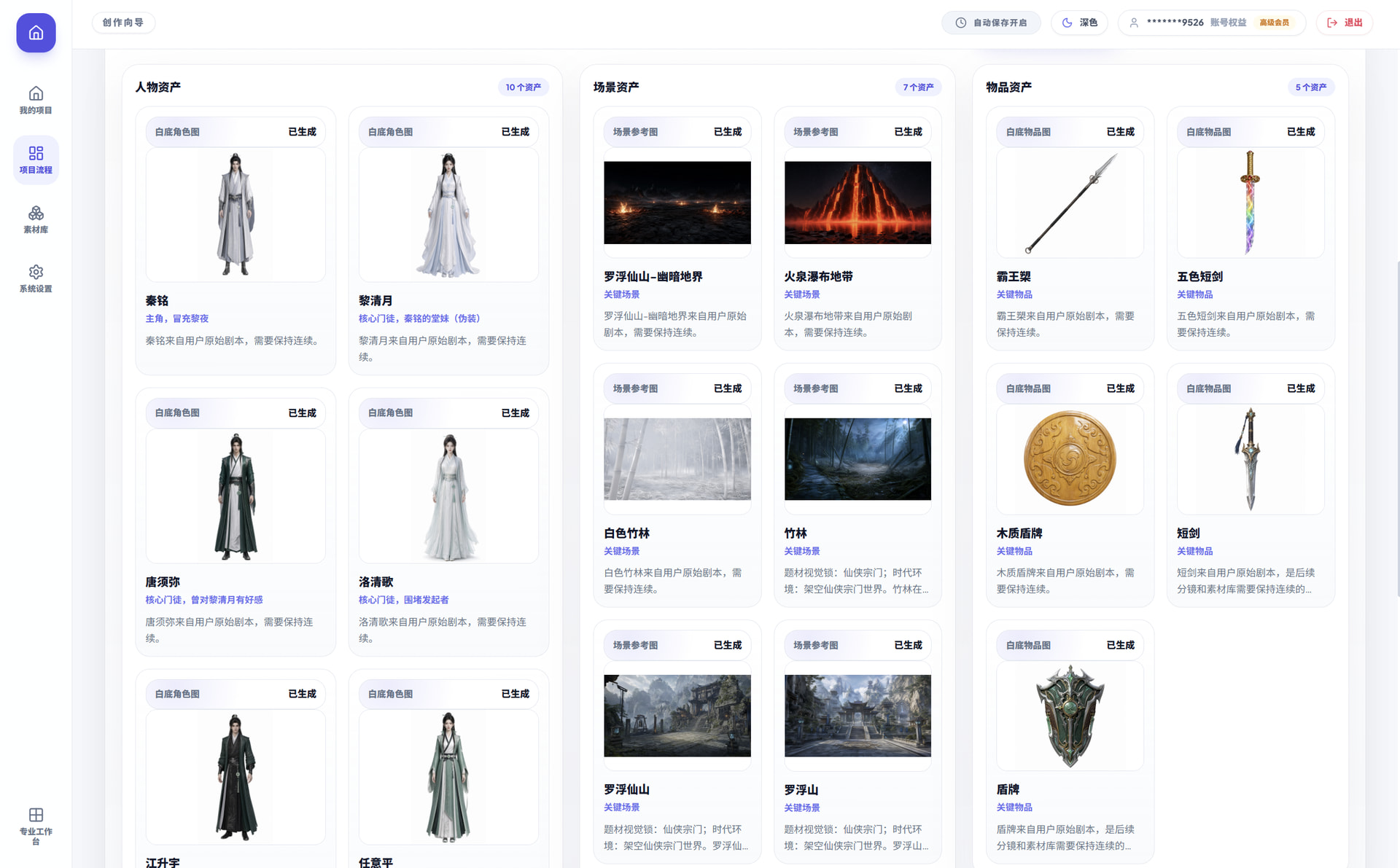

当然了,对于进入资产库的人物、场景、物品还需要更精准的一致性锚定,所以需要把人物的情绪图、多维视角图,场景的空间多维图、物品的视角图生成出来,这样才能更好的在生图环节保持人物的一致性以及人物对于空间的理解逻辑。
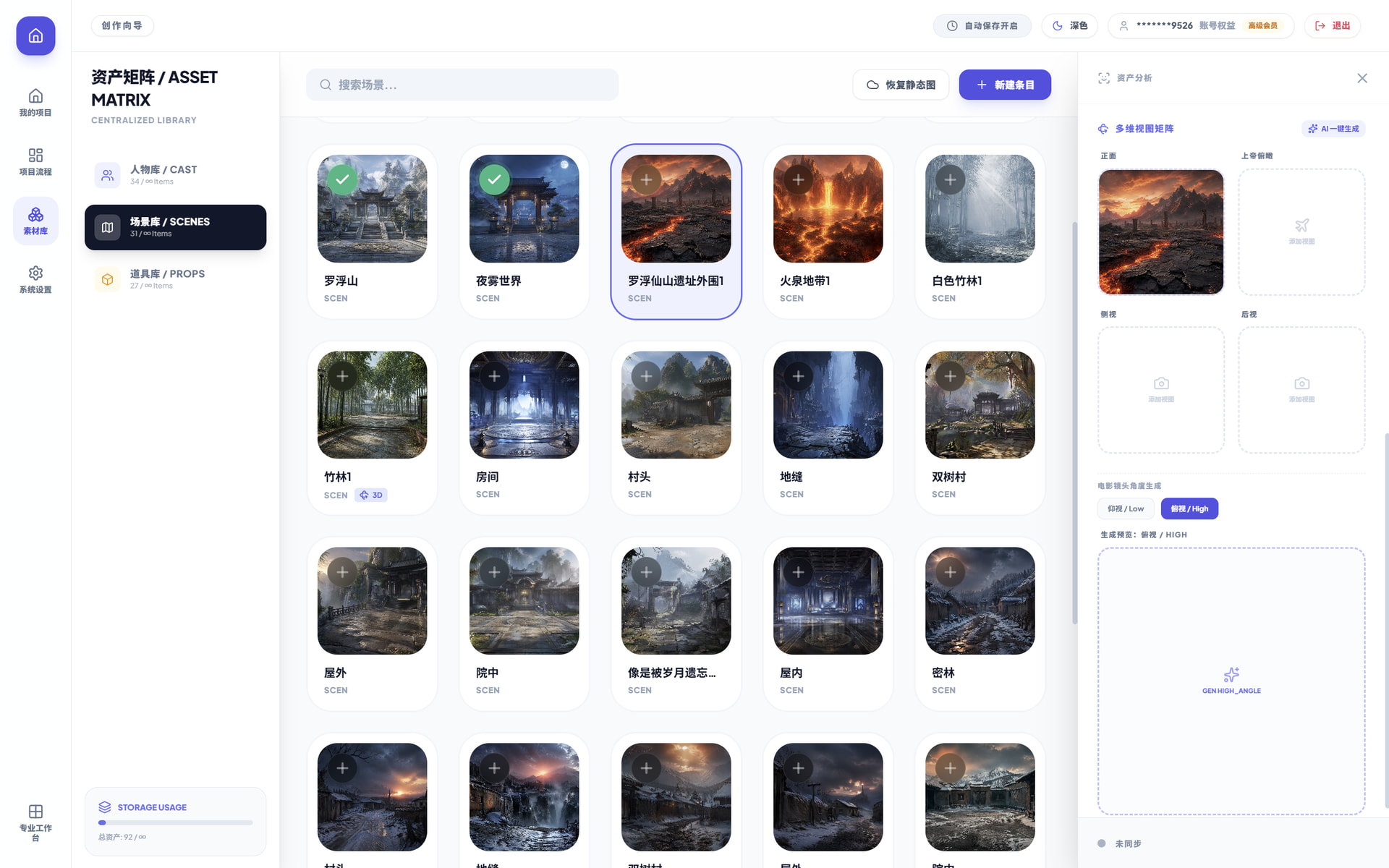
然后就是根据分集内容输出对应的分镜脚本,分镜脚本会把每一分镜的画面提示词、视频提示词、人物台词全部输出出来,接下来就是重头戏啦,考虑到很多人嫌麻烦,所以增加了人为调控的并发按钮------①如果想要每个画面都有上下连贯且有叙事性,那就一张一张生成吧②当然如果你觉得太慢了,也可以选择3张并发③还有人觉得依然慢的,那就可以选择5张生图并发的模式,但牺牲的是前后叙事的连贯性,但是每批次的5张生图的叙事连贯性依然存在。
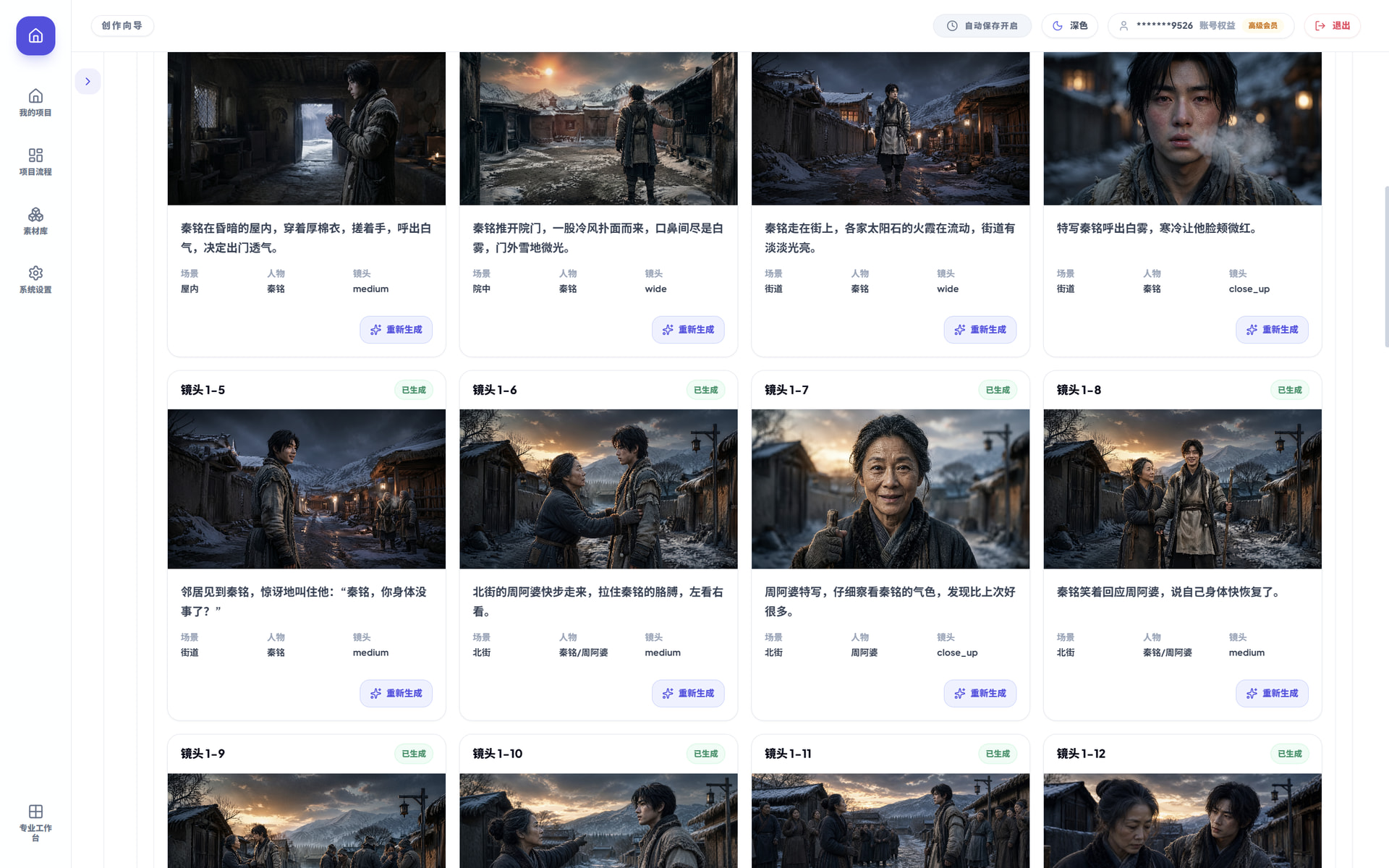
在考虑到输出音画同步的视频质量效果可能不会太好的情况下,所以增加了一个后续语音配音功能,这个主要是弥补有些视频的人物台词表达不清晰或者胡言乱语的情况,这就需要后续用同样的声线输出对应的台词,在剪辑阶段进行弥补了,毕竟我们奔着是做精品漫剧的方向前行的。
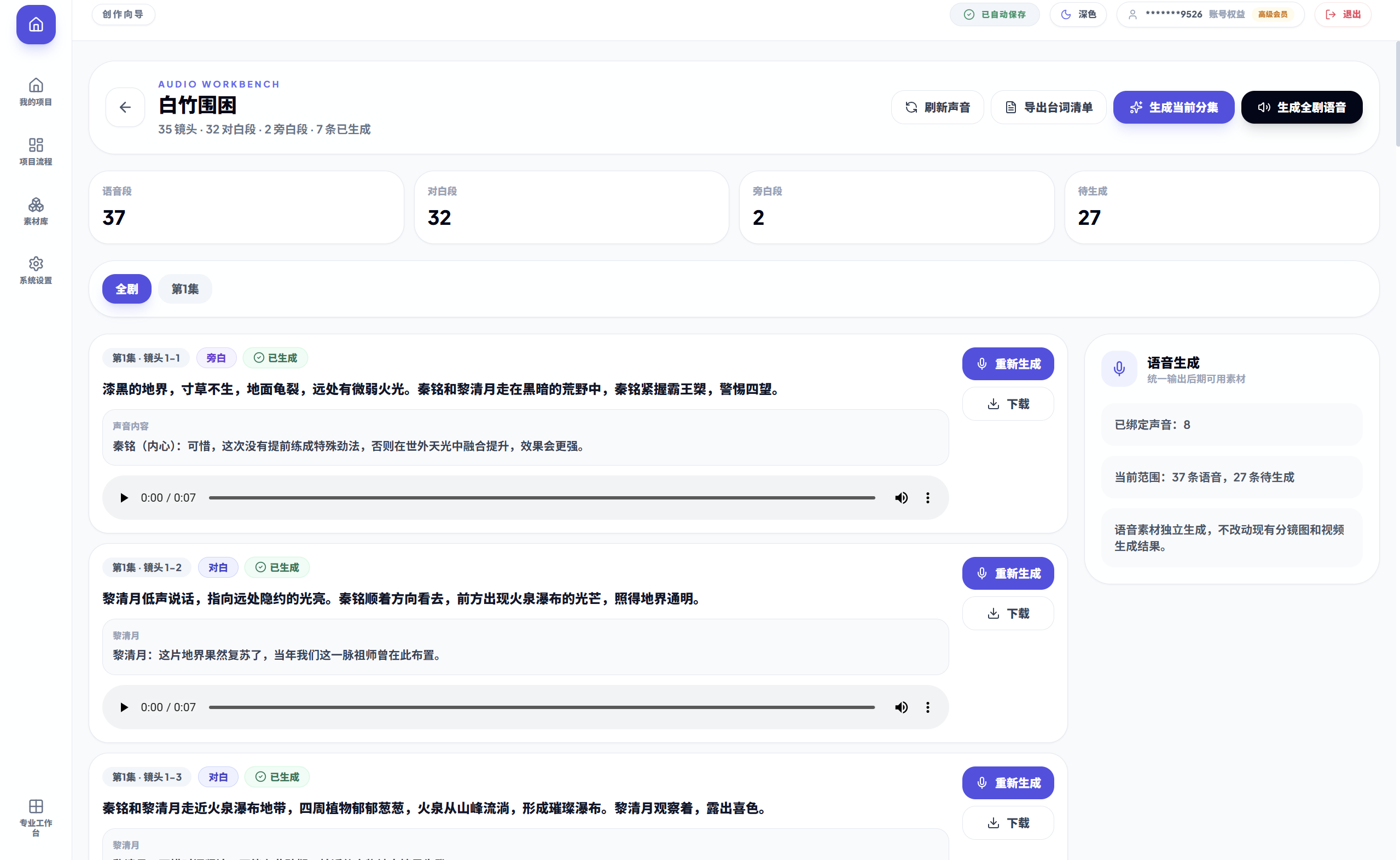
最后就来到我们的终点------视频输出页,目前视频的一致性、音画同步的效果都表现还不错,更多的是使用grok模型测试的,其他成本较高的模型的测试比较少,但只能说效果和质量会更好,因为我接入官方seedance2.0模型,测试8S视频就花了我8块钱,肉疼啊。
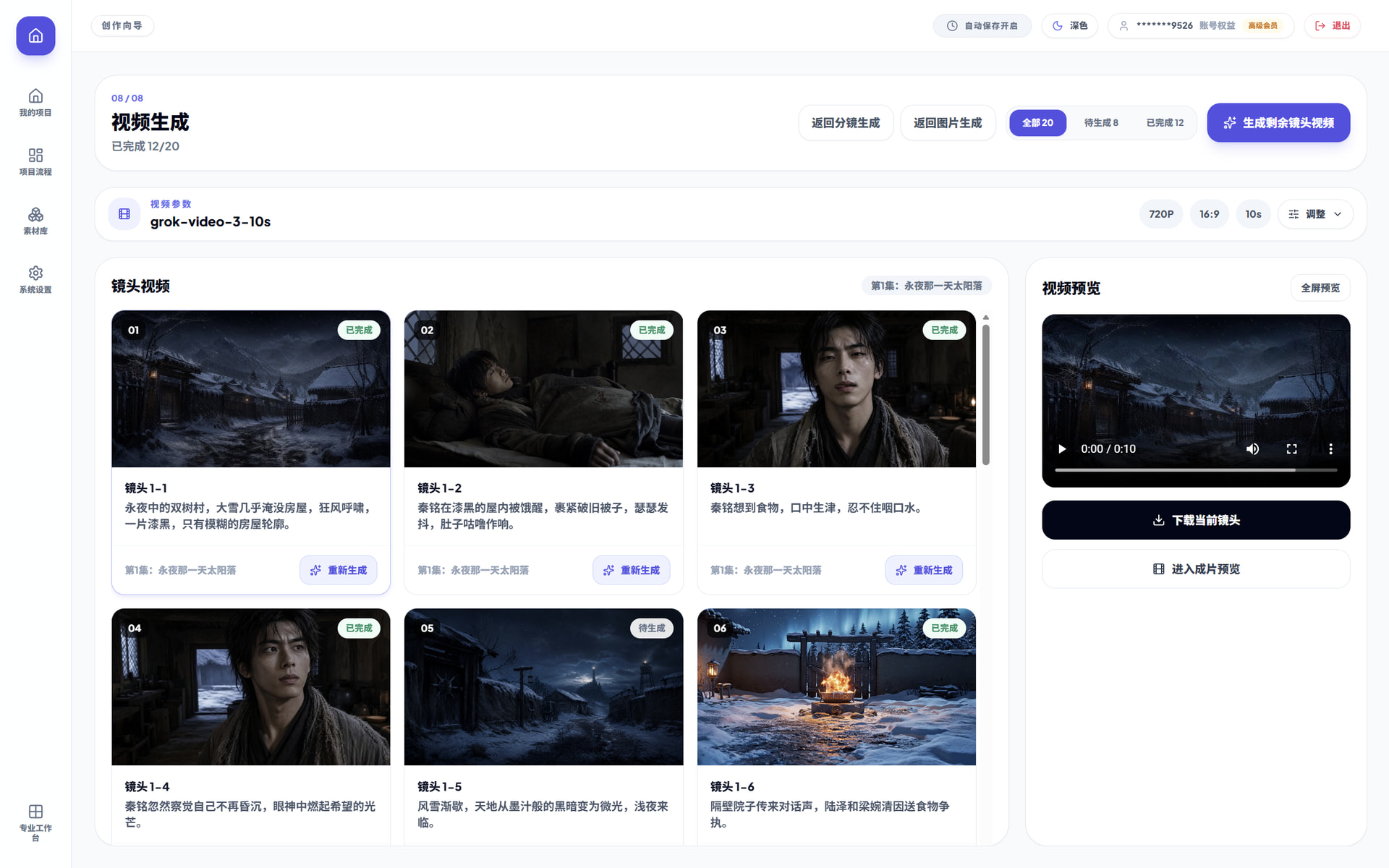
最后呢,还是想说一句,该应用前前后后打磨的时间差不多3个月了,可能跟我的星座有关,总想着把功能做全做好,因为最初的目的就是想通过它能自动化产出高质量的视频或者短剧,每当我快要收尾的时候,又觉得还可以再打磨一下。
截至到现在,脚本测试不下于上百个、图片一致性测试已经输出了几千张、视频效果测试也生成了几百个,整体来说过程还是比较坎坷,但欣慰的是目前能达到的效果还是不错的,因为我一直在用效果较差的VEO模型和Grok模型实测,如果接入国产的可灵、seedance2.0模型只会更好。
今天就记录到这里,下次有新的进展会持续更新!
6 个帖子 - 4 位参与者