llama.cpp 搭建本地模型
使用llama.cpp 搭建本地模型。具体来说,就是在本地终端电脑跑上自己的模型。
- 能跑什么模型,多大的模型,要根据自己的电脑配置,配置越高,跑的越大;显卡+内存
- 为啥能跑? 把模型塞到内存中了,所以没显卡也能跑,但就是慢。
- b的单位补充。1B = 10亿参数 。 通常看到模型8b,啥意思呢,就是模型参数是80亿;deepseek v4 pro ,1.6万亿参数,也就是1.6T; v4-pro 是284B
- deepseek目前都是MoE 架构,就是比如dddddddd v4-pro 284b参数,每次chat不是全部都调用,而只是调用激活的参数,激活13B,就是130亿参数。 MOE是把所有的参数都放到内从中,因为显存太大了,一般8B *2 要16G 的显卡,那么284B要多大呢? 1.6T要多大呢?所以绝大多数都放在内存中不激活,激活的就是公共参数比如13B。然后根据公共参数,去调用需要的在内从的专家参数。
1.下载llama.cpp
- 这里下载对应电脑的版本
https://github.com/ggml-org/llama.cpp/releases
2 下载自己电脑所能够配置的模型
2.1 模型下载的地址
Hugging Face DeepSeek-V4 - a deepseek-ai Collection 魔搭社区 (ModelScope)- 国内的 ModelScope - 模型列表页
2.2 下载模型
-
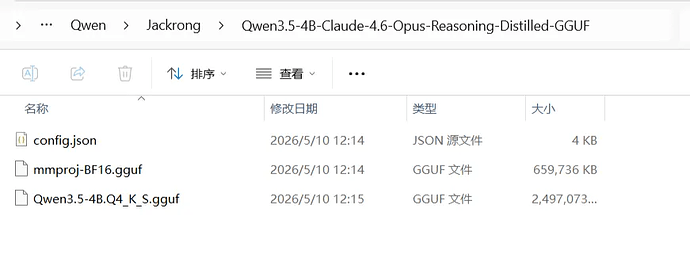
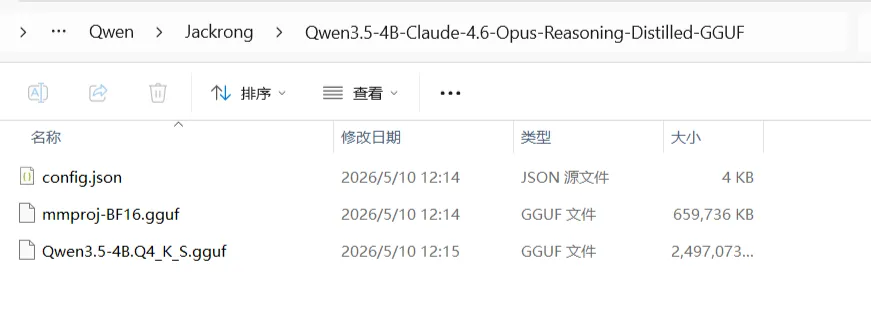
一般现在xxx Q4_K_M.gguf, 比如 Qwen3.5-9B-Q4_K_M.gguf
-
因为这个模型是量化过的,9B的模型一般16精度要18G的显卡,但是量化过了,就只需要5到6G显卡,比这个高,需要的显卡要大,比这个低,模型就变傻了;结论这个就是最高性价比
-
如上的文件都不能少。但是在官网有很多文件,量化的很多,下载下来浪费时间和磁盘,所以选择适合自己的。
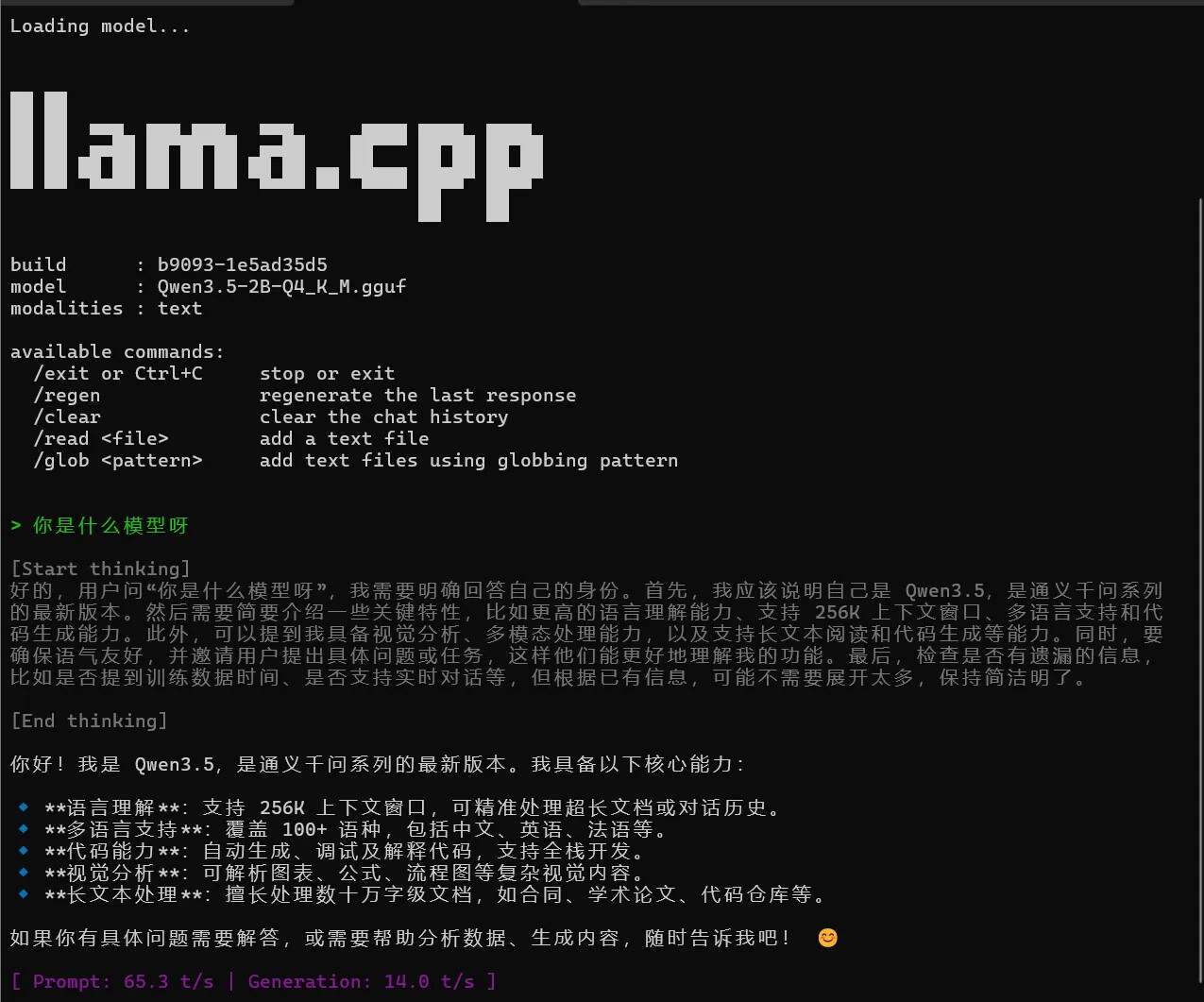
如何让模型和llma.cpp 在终端上跑起来呢?
.\llama-cli.exe -m "C:\xxxx\Qwen\Jackrong\Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF\Qwen3.5-4B.Q4_K_S.gguf" -n 2048 -ngl 15
命令分解
参数 值 含义.\llama-cli.exe
-
当前目录下的 llama-cli 可执行文件(llama.cpp 的 CLI 工具)
-m
"C:\xxxx\Qwen\Jackrong\Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF\Qwen3.5-4B.Q4_K_S.gguf"
指定模型文件路径(一个经过 GGUF 量化、蒸馏处理的 Qwen3.5 模型)
-n
2048
生成的最大 token 数量(最多生成 2048 个新 token)
-ngl
15
GPU 层数 :将模型的前 15 层加载到 GPU 中运行,剩余层在 CPU 上运行
实际效果
总结:
其实,这个就是一个思路,如何在本地搭建自己的大模型。主要受限制的是硬件,如果硬件给力,24G显卡+500G内存,可以把deepseekv4-falsh 搭建在自己电脑上,想想多快乐,再也不用愁tokens了。
文章分析的内容,其实不难,一步步在ai的帮助下都可以自己实现,如有不懂,随时发问。如有不对,请多指教包含。
6 个帖子 - 4 位参与者
来源: LinuxDo 最新话题查看原文