写在前面
PS: 只要不想着团队能力,功能开发起来就是快多了 ![]()
项目SamePage-AI核心功能实现后。最近基于对话能力测试时发现回复总是一段一段的出现,真是不抽打 AI 它就在偷懒啊,于是需要一次能力补全。
后端是基于 ChatOpenAI 包了一层,查看接口也没有任何问题,所以直接观测前端吧。
渲染优化
核心:减少不必要的渲染次数
原本是这样:
数据源每接收到一次 streaming delta,computed 就立刻重跑一次。数据返回太快,用户又不关心中间过程,自然可以联想到一些策略。
flush 策略
模型尤其是 flash 模型蹿稀式输出回复,可以对输出进行缓存。
- 固定间隔 flush:太短间隔用户视觉无法察觉,给定一个舒适的时间
- 结构边界 flush:从普通文本追加切换到换行、标题、列表块、代码块等其他块时需要主动 flush
复用策略
一个长的回答里可能会存在多个块,尤其是换行后前面的内容大概率已经稳定了,不会从一个代码块突然变成表格。
复用需要进行多层配合:
- MarkdownIt 实例复用,全局共享
- markdown block 渲染结果复用,流式结果分割为多个 block,新的 block 不影响旧的 block
- Vue DOM 节点复用,基于 key 就行,底层由 Vue 进行保证
虚拟列表
渲染优化哪有不使用虚拟列表方案的呢,核心就是只渲染视口附近消息,历史消息不再常驻 DOM。
打字机优化
得益于切换到 flash 模型蹿稀式返回,每次返回一大段感觉界面在闪烁,体验很差。同样需要引入显示缓冲区概念。前文提及的拆分为多个 blocks 已经提供了稳定性了,只要取 blocks.at(-1) 最后一个 block 就能得到打字机要输出的内容。
当然这也有坑需要继续优化,如果正文是每次是十多个字符,那么动画还跟得上,但 thinking 部分往往是几十个字符,导致思考打字机动画和正文同时了,当前偷鸡解决为“正文开始直接折叠 thinking,且字符全部塞入”。当前的动画效果还不错:
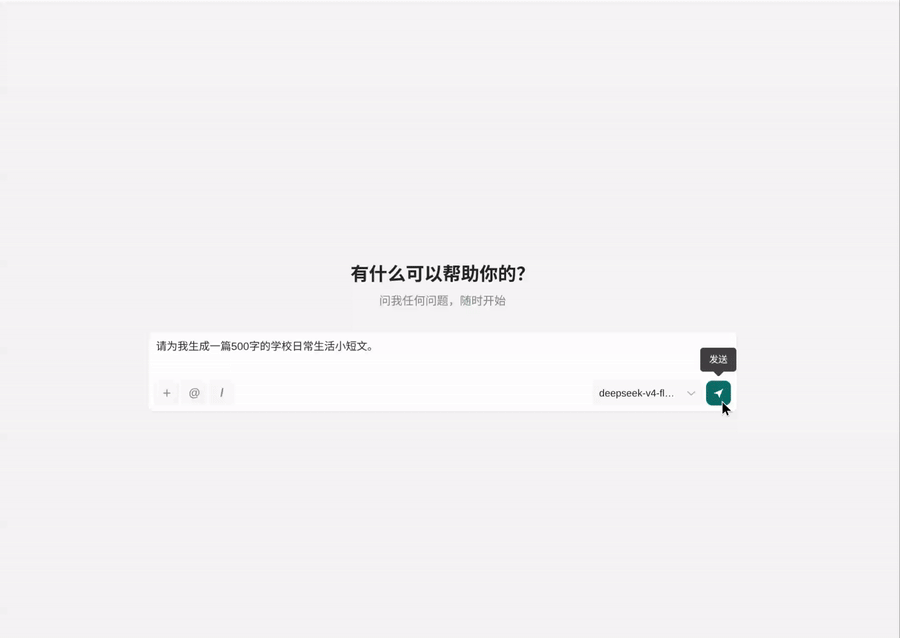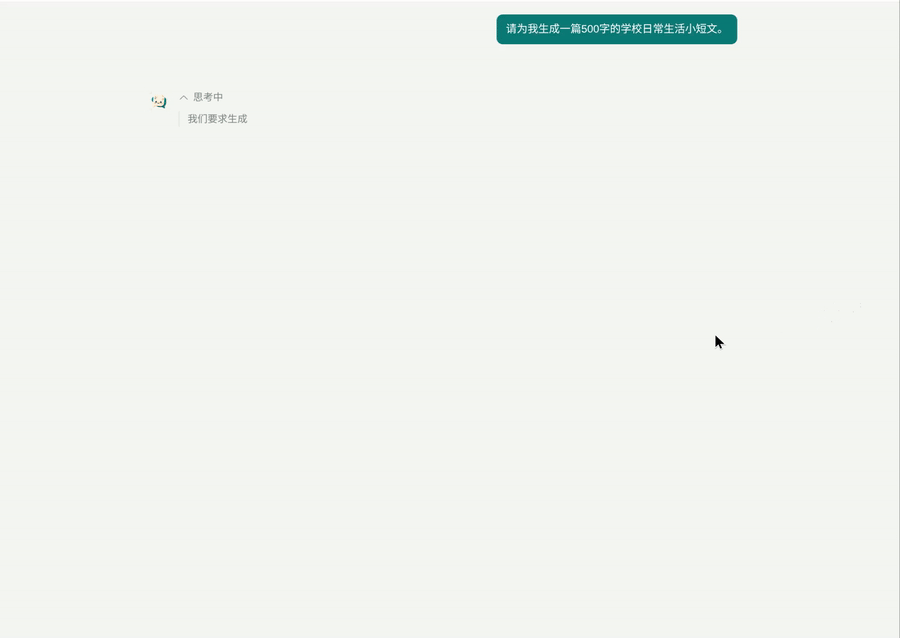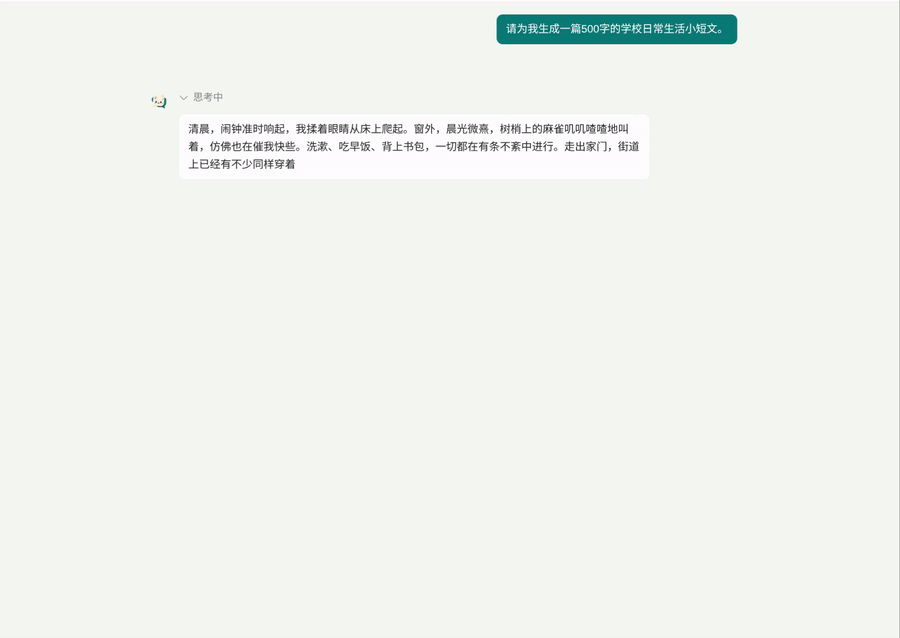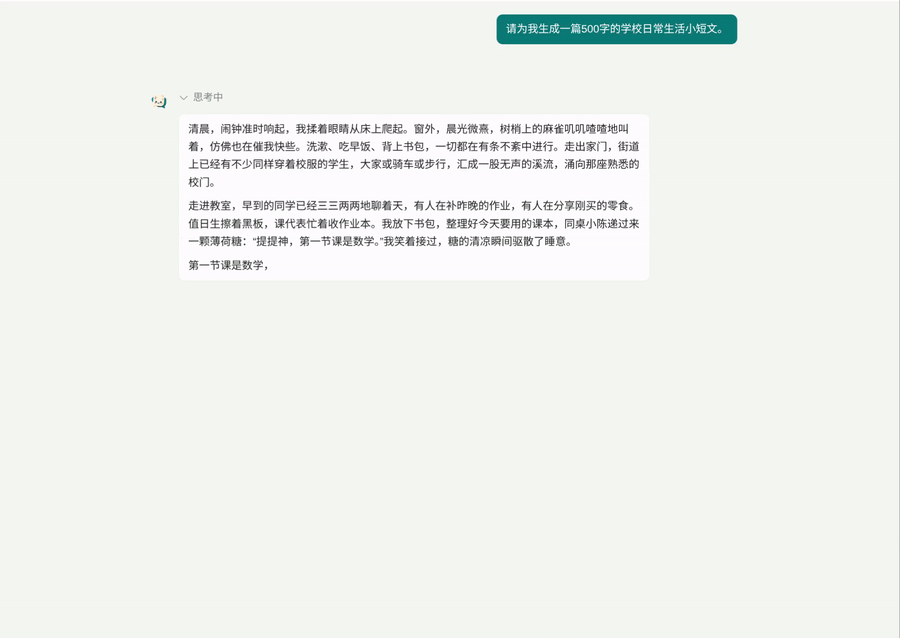
1 个帖子 - 1 位参与者
来源: LinuxDo 最新话题查看原文