太久没上论坛,感觉发生了翻天覆地的变化。最近在给公司做Dify企业应用开发,学到了很多新东西,给佬们开开眼界。
起因是要设计图文混排的工作流(workflow),因为是后端异步调用dify,所以不用担心耗时的问题。因此最初我的设计是先让LLM输出完整的内容,然后再让另一个LLM理解这些内容,输出一个对象数组,每个对象包含文生图提示词以及图片在内容中的位置(这里采用的方案是按\n\n分割内容,然后计算图片在分割数组中的索引),循环调用文生图工具,将图片上传oss后将oss地址插入到内容中,最后返回。
最近提了个新需求,要求给dify的对话流(chatflow)开发图文混答,由于这次是文本图片采用流式输出,就必须考虑耗时的问题了。然而市面上的教程清一色的都是构建知识库,然后在知识库文档中引入图片地址,这样AI检索到图片地址就能完整的输出。但是这种方式非常依赖知识库,而我们的场景主要是医疗领域(产品很多地方借鉴了阿福,只不过我们是针对私域的,而非公众通用),知识库数量庞大,并且维护困难。
就在我一筹莫展之际,我找到了这篇文章:
 baijiahao.baidu.com
baijiahao.baidu.com
苹果研究团队:AI实现图文理解与生成统一框架能力提升突破
通过AI解读和理解之后,给出方案为先规划后生成,并且用两个迭代节点并行生成文字和图片,通过代码调度控制输出的节奏。比如:规划LLM给出一个对象数组,大致如下
[
{
"id": "text_1",
"content": "第一板块的概括内容",
"depends": [],
"index": 0
},
{
"id": "image_1",
"content": "基于[text_1]的内容,生成图片:高科技宣传图,蓝色主色,未来风",
"depends": ["text_1"],
"index": 1
},
{
"id": "text_2",
"content": "第二板块的概括内容",
"depends": ["image_2"],
"index": 2
}
]
完成生成的内容会写入队列(Redis),每次输出前都会从完成队列中读取所有未消费的项,判断当前项是否有依赖,依赖项是否完成,是否消费,同时依赖项的依赖项是否完成以及是否消费(递归),满足条件的按照index排序,确保输出顺序正确,最后拼接和输出。当然,这里我只是简单概括,实际逻辑要更复杂,大概是这么个意思。
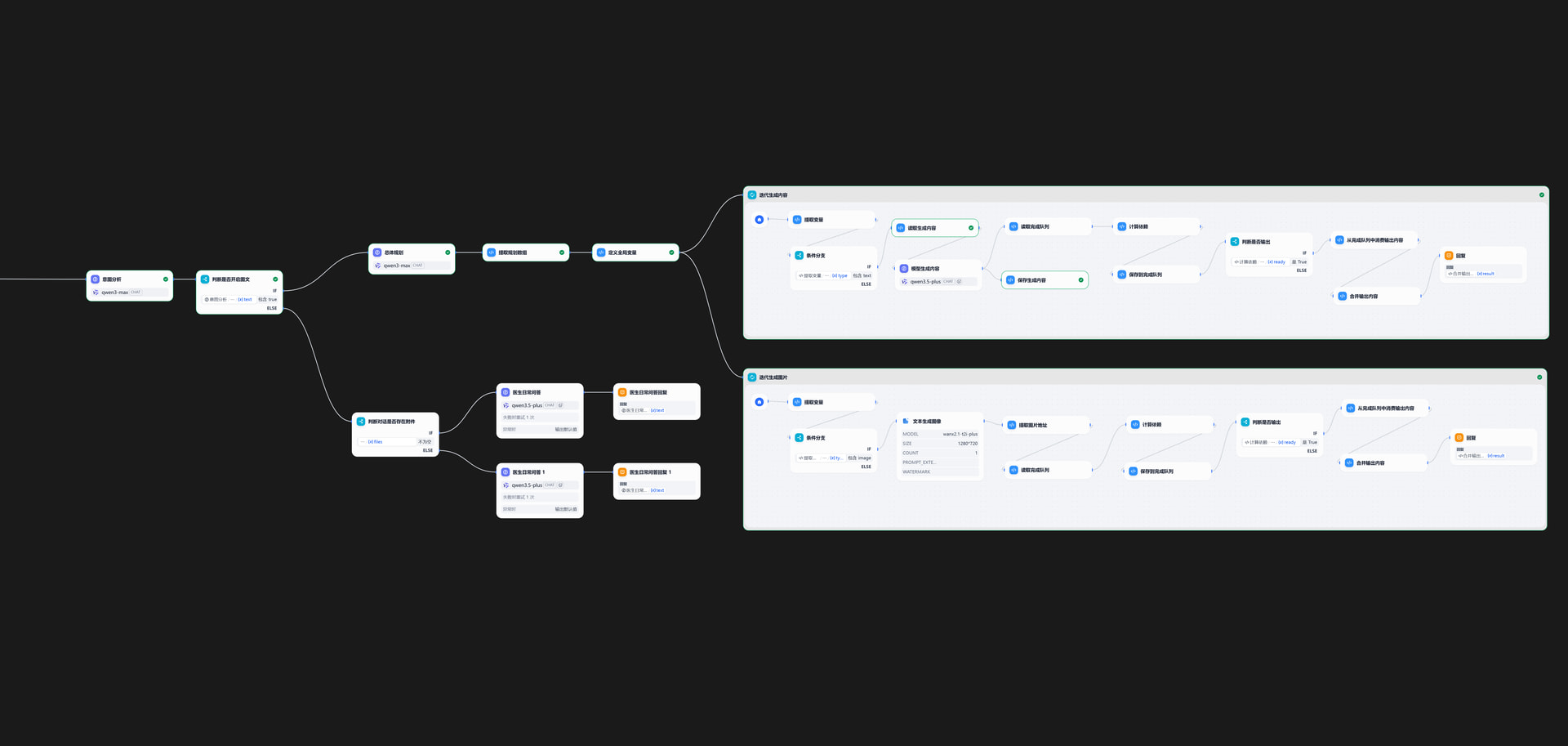
测试流程效果:

现阶段的问题还是出现在循环里的文字生成LLM的提示词不够完善,由于架构的弊端,AI每次循环生成的段落可能重复,加上有一些特殊的业务需求,模型不给力就靠蒙,只能用qwen3.5plus才能勉强满足要求。
不过工程问题都好解决,优化一下速度还是能够落地的。
1 个帖子 - 1 位参与者